
C++20: The Advantages of Modules
Modules are one of the four big features of C++20: concepts, ranges, coroutines, and modules. Modules promise a lot: compile-time improvement, isolation of macros, the abolition of header files, and ugly workarounds.
Why do we need modules? I want to step back and describe the steps involved in getting an executable.
A Simple Executable
Of course, I have to start with “Hello World”.
// helloWorld.cpp #include <iostream> int main() { std::cout << "Hello World" << std::endl; }
Making an executable helloWorld out of the program helloWorld.cpp increases its size by a factor 130.
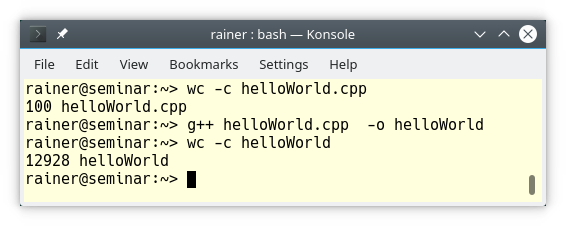
The numbers 100 and 12928 in the screenshot stand for the number of bytes.
We should have a basic understanding of what’s happening under the hood.
The classical Build Process
The build process consists of three steps: preprocessing, compilation, and linking.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Be part of my mentoring programs:
Do you want to stay informed: Subscribe.
Preprocessing
The preprocessor handles the preprocessor directives such as #include and #define. The preprocessor substitutes #inlude directives with the corresponding header files, and it substitutes the macros (#define). Thanks to directives such as #if, #else, #elif, #ifdef, #ifndef, and #endif parts of the source code can be included or excluded.
This straightforward text substitution process can be observed using the compiler flag -E on GCC/Clang, or /E on Windows.
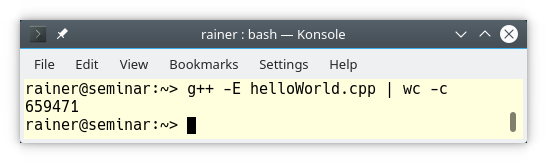
WOW!!! The output of the preprocessing step has more than half a million bytes. I don’t want to blame GCC; the other compilers are similar verbose: CompilerExplorer.
The output of the preprocessor is the input for the compiler.
Compilation
The compilation is separately performed on each output of the preprocessor. The compiler parses the C++ source code and converts it into assembly code. The generated file is called an object file, containing the compiled code in binary form. The object file can refer to symbols that don’t have a definition. The object files can be put in archives for later reuse. These archives are called static libraries.
The objects or translation units the compiler produces are the input for the linker.
Linking
The linker’s output can be executable, static, or shared library. The linker’s job is to resolve the references to undefined symbols. Symbols are defined in object files or libraries. The typical error in this state is that symbols aren’t defined or defined more than once.
This build process consisting of the three steps is inherited from C. It works sufficiently well enough if you only have one translation unit. But when you have more than one translation unit, many issues can occur.
Issues of the Build Process
Without any attempt to complete it, the classical build process has flaws. Modules overcome these issues.
Repeated substitution of Headers
The preprocessor substitutes #include directives with the corresponding header files. Let me change my initial helloWorld.cpp program to make the repetition visible.
I refactored the program and added two source files hello.cpp and world.cpp. The source file hello.cpp provides the function hello and the source file world.cpp provides the function world. Both source files include the corresponding headers. Refactoring means that the program does the same such as the previous program helloWorld.cpp. The internal structure is changed. Here are the new files:
- hello.cpp and hello.h
// hello.cpp #include "hello.h" void hello() { std::cout << "hello "; }
// hello.h #include <iostream> void hello();
- world.cpp and world.h
// world.cpp #include "world.h" void world() { std::cout << "world"; }
// world.h #include <iostream> void world();
- helloWorld2.cpp
// helloWorld2.cpp #include <iostream> #include "hello.h" #include "world.h" int main() { hello(); world(); std::cout << std::endl; }
Building and executing the program works as expected:
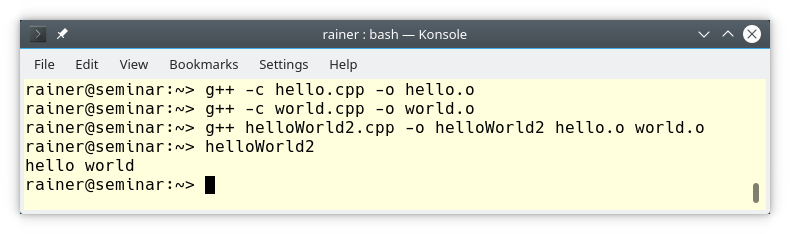
Here is the issue. The preprocessor runs on each source file. This means that the header file <iostream> is included three times in each translation unit. Consequently, each source file is blown up to over half a million lines.
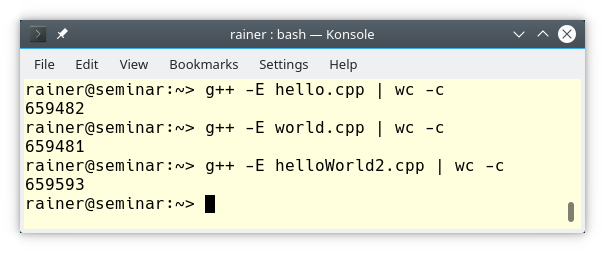
This is a waste of compile time.
In contrast, a module is only imported once and is literally for free.
Isolation from Preprocessor Macros
If there is one consensus in the C++ community, it’s the following: we should eliminate the preprocessor macros. Why? Using a macro is just text substitution, excluding any C++ semantics. Of course, this has many negative consequences: For example, it may depend on in which sequence you include macros, or macros can clash with already defined macros or names in your application.
Imagine you have two headers webcolors.h and productinfo.h.
// webcolors.h #define RED 0xFF0000
// productinfo.h #define RED 0
When a source file client.CPP includes both headers, the value of the macro RED depends on the sequence the headers are included. This dependency is very error-prone.
In contrast, it makes no difference in which order you import modules.
Multiple Definitions of Symbols
ODR stands for the One Definition Rule and says in the case of a function.
- A function can have not more than one definition in any translation unit.
- A function can have not more than one definition in the program.
- Inline functions with external linkage can be defined in more than one translation. The definitions must satisfy the requirement that each must be the same.
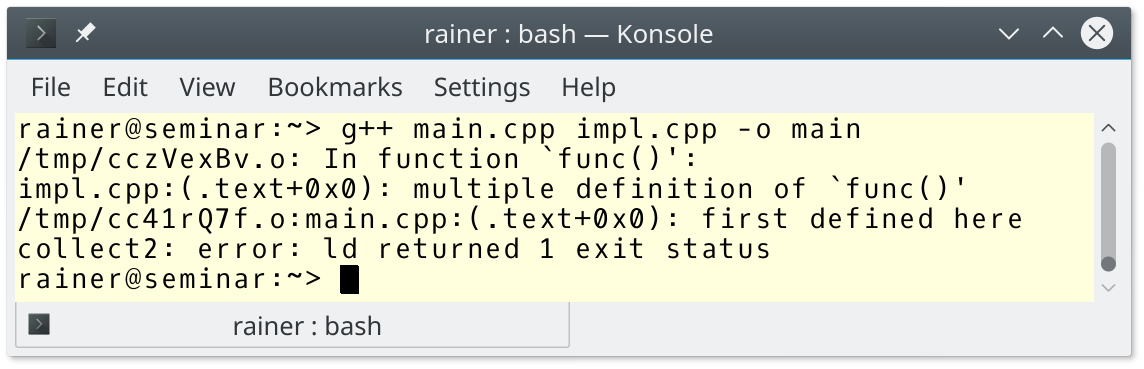
Let me see what my linker says when I try to link a program breaking the one-definition rule. The following code example has two header files header.h and header2.h. The main program includes the header file header.h twice and, therefore, break the one definition rule because two definitions of func are included.
// header.h void func() {}
// header2.h #include "header.h"
// main.cpp #include "header.h" #include "header2.h" int main() {}
The linker complains about the multiple definitions of func:
We are used to ugly workarounds such as putting an include guard around your header. Adding the include guard FUNC_H to the header file header.h solves the issue.
// header.h #ifndef FUNC_H #define FUNC_H void func(){} #endif
In contrast, identical symbols with modules are very unlikely.
Before I end this post, I want to summarize the advantages of modules.
Advantages of Modules
- Modules are only imported once and are literally for free.
- It makes no difference in which order you import a module.
- Identical symbols with modules are very unlikely.
- Modules enable you to express the logical structure of your code. You can explicitly specify names that should be exported or not. Additionally, you can bundle a few modules into a bigger module and provide them to your customer as a logical package.
- Thanks to modules, there is no need to separate your source code into an interface and an implementation part.
What’s next?
Modules promise a lot. In my next post, I will define and use my first module.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Phillip Diekmann, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery,and Matt Godbolt.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Seminars
I’m happy to give online seminars or face-to-face seminars worldwide. Please call me if you have any questions.
Standard Seminars (English/German)
Here is a compilation of my standard seminars. These seminars are only meant to give you a first orientation.
- C++ – The Core Language
- C++ – The Standard Library
- C++ – Compact
- C++11 and C++14
- Concurrency with Modern C++
- Design Pattern and Architectural Pattern with C++
- Embedded Programming with Modern C++
- Generic Programming (Templates) with C++
- Clean Code with Modern C++
- C++20
Online Seminars (German)
- Embedded
Programmierung mit modernem C++ (2. Jul 2024 bis 4.
Jul 2024)
Contact Me
- Mobil: +49 176 5506 5086
- Mail: schulung@ModernesCpp.de
- German Seminar Page: www.ModernesCpp.de
- Mentoring Page: www.ModernesCpp.org
Modernes C++ Mentoring,









Leave a Reply
Want to join the discussion?Feel free to contribute!