
Optimization with Allocators in C++17
Thanks to polymorphic allocators in C++17, you can optimize your memory allocation. This optimization includes performance and the reuse of memory.
Performance
The following program is from cppreference.com/monotonic_buffer_resource. I will explain and extend its performance test to Clang and the MSVC compiler.
// pmrPerformance.cpp // https://en.cppreference.com/w/cpp/memory/monotonic_buffer_resource #include <array> #include <chrono> #include <cstddef> #include <iomanip> #include <iostream> #include <list> #include <memory_resource> template<typename Func> auto benchmark(Func test_func, int iterations) // (1) { const auto start = std::chrono::system_clock::now(); while (iterations-- > 0) test_func(); const auto stop = std::chrono::system_clock::now(); const auto secs = std::chrono::duration<double>(stop - start); return secs.count(); } int main() { constexpr int iterations{100}; constexpr int total_nodes{2'00'000}; auto default_std_alloc = [total_nodes] // (2) { std::list<int> list; for (int i{}; i != total_nodes; ++i) list.push_back(i); }; auto default_pmr_alloc = [total_nodes] // (3) { std::pmr::list<int> list; for (int i{}; i != total_nodes; ++i) list.push_back(i); }; auto pmr_alloc_no_buf = [total_nodes] // (4) { std::pmr::monotonic_buffer_resource mbr; std::pmr::polymorphic_allocator<int> pa{&mbr}; std::pmr::list<int> list{pa}; for (int i{}; i != total_nodes; ++i) list.push_back(i); }; auto pmr_alloc_and_buf = [total_nodes] // (5) { std::array<std::byte, total_nodes * 32> buffer; // enough to fit in all nodes std::pmr::monotonic_buffer_resource mbr{buffer.data(), buffer.size()}; std::pmr::polymorphic_allocator<int> pa{&mbr}; std::pmr::list<int> list{pa}; for (int i{}; i != total_nodes; ++i) list.push_back(i); }; const double t1 = benchmark(default_std_alloc, iterations); const double t2 = benchmark(default_pmr_alloc, iterations); const double t3 = benchmark(pmr_alloc_no_buf , iterations); const double t4 = benchmark(pmr_alloc_and_buf, iterations); std::cout << std::fixed << std::setprecision(3) << "t1 (default std alloc): " << t1 << " sec; t1/t1: " << t1/t1 << '\n' << "t2 (default pmr alloc): " << t2 << " sec; t1/t2: " << t1/t2 << '\n' << "t3 (pmr alloc no buf): " << t3 << " sec; t1/t3: " << t1/t3 << '\n' << "t4 (pmr alloc and buf): " << t4 << " sec; t1/t4: " << t1/t4 << '\n'; }
This performance test in line (1) executes the functions in lines 2 – 5 one hundred times (constexpr int iterations{100}) . Each call of the functions creates a std::pmr::list<int> of two hundred thousand nodes (constexpr int total_nodes{2'00'000}). The nodes of each list are allocated in different ways:
- Line 2:
std::list<int>uses the globaloperator new - Line 3:
std::pmr::list<int>uses the special memory resourcestd::pmr::new_delete_resource - Line 4:
std::pmr::list<int>usesstd::pmr::monotonic_bufferwithout a preallocated buffer on the stack - Line 5:
std::pmr::listusesstd::pmr::monotonic_bufferwith a preallocated buffer on the stack
The comment to the last function (line 5) states that the stack has enough space to fit all nodes: “enough to fit in all nodes“. This was correct on my Linux PC but not on my Windows PC. On Linux, the default for the stack size is 8 MB, but on Windows only 1 MB. Consequentially, my program execution on Windows using the MSVC compiler and the Clang compiler failed silently. I fixed it by changing with the help of editbin.exe the stack size of my MSVC and Clang executables:

Finally, here are the numbers. The reference value is the allocation with std::list<int> (line 2). Don’t compare the absolute numbers but the relative numbers because I used a virtualized Linux PC and a non-virtual Windows PC. Additionally, I enabled full optimization. This means (/Ox) for the MSVC compiler and (-Ox) for the GCC and Clang compilers.
- Clang Compiler
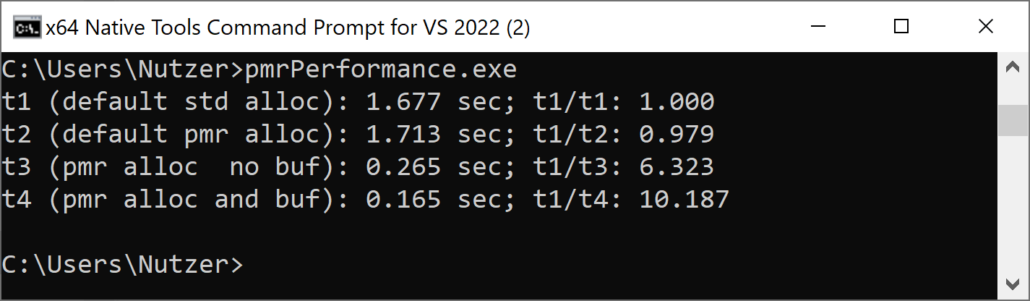
- GCC Compiler
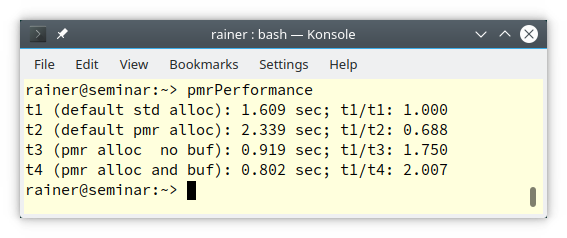
- MSVC Compiler
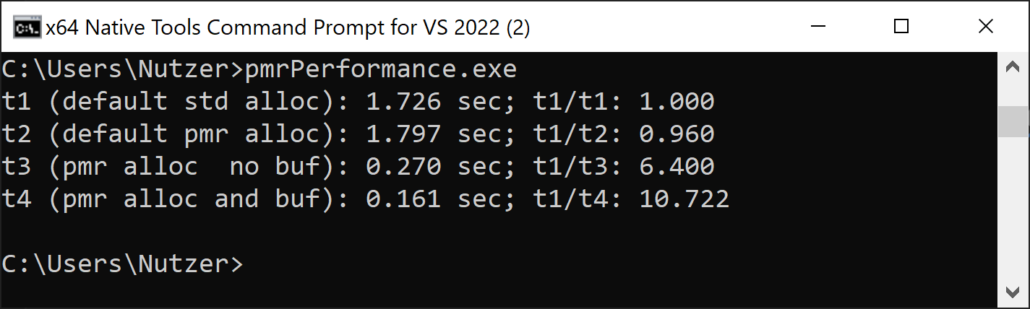
Interestingly, the memory resource std::pmr::new_delete_resource was always the slowest memory allocation. On the contrary, std::pmr::monotonic_buffer the fastest memory allocation. This holds particularly if you use a preallocated buffer on the stack. On Windows, memory allocation is about 10 times faster.
There is another optimization potential of std::pmr::new_delete_resource.
Memory Reuse
std::pmr::monotonic_buffer enables the reuse of memory, and you can, therefor, spare the to free the memory.
// reuseMemory.cpp #include <array> #include <cstddef> #include <iostream> #include <memory_resource> #include <string> #include <vector> int main() { std::array<std::byte, 2000> buf; for (int i = 0; i < 100; ++i) { // (1) std::pmr::monotonic_buffer_resource pool{buf.data(), buf.size(), // (2) std::pmr::null_memory_resource()}; std::pmr::vector<std::pmr::string> myVec{&pool}; for (int j = 0; j < 16; ++j) { // (3) myVec.emplace_back("A short string"); } } }
This program allocated a std::array of 2000 bytes : std::array<std::byte, 2000>. This stack-allocated memory is reused 100 times (line 1). The std::pmr::vector<std::prm::string> uses the std::pmr::monotonic_buffer_resource with the upstream memory resource std::pmr::null_memory_resource (line 2). Finally, 16 strings are added to the vector.
What’s Next?
This post ends my min-series about the polymorphic memory resources in C++17. In my next post, I will jump three years further and continue my journey through C++20.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org








