
Copy versus Move Semantics: A few Numbers
A lot was written about the advantages of move semantics to copy semantics. Instead of an expensive copy operation, you can use a cheap move operation. But what does that mean? In this post, I will compare the copy and move semantics performance for the Standard Template Library (STL) containers.
Before I show the number, I will provide some background information.
Copy versus Move Semantics
The subtle difference is if you create with a copy or move semantic a new object based on an existing one, the copy semantic will copy the elements of the resource, and the move semantic will move the elements of the resource. Of course, copying is expensive, and moving is cheap. But there are additional serious consequences.
- With copy semantic, it can happen that a std::bad_alloc will be thrown because your program is out of memory.
- The resource of the move operation is afterward in a “valid but unspecified state“.
The second point is very nice to show with std::string.
At first, the classical copy semantics.
Copy semantics
std::string1("ABCDEF");
std::string str2;
str2 = str1;
After the copy operation, strings str1 and str2 have the same content, “ABCDEF“. So, what’s the difference between the move semantics?
Move semantics
std::string1("ABCDEF");
std::string str3;
str3 = std::move(str1);

The string str1 opposes the copy semantic afterward empty “”. This is not guaranteed but often the case. I explicitly requested the move semantic with the function std::move. The compiler will automatically perform the move semantic if it is sure that the source of the move semantic is not needed anymore.
I will explicitly request the move semantic in my program by using std::move.
The Performance Differences
I will take the naive position in my post and compare the performance difference between the copy and move semantics of the STL containers. My comparison will include the std::string. I will ignore the associative containers, which can have more equal keys. I’m particularly interested in the performance ratio between the copy and move semantics of the containers.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
The boundary conditions
The differences were not so dramatic between the program with maximum optimization and without optimization; therefore, I will, for simplicity reasons, only provide the results for the executable with maximum optimization. I use a GCC 4.9.2 compiler and the cl.exe compiler, which is part of Microsoft Visual Studio 2015. Both platforms are 64-bit. Therefore, the executables are built for 64-bit.
The program
We have a lot of containers in the STL. Therefore, the program is a little bit lengthy.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 |
// movePerformance.cpp #include <array> #include <forward_list> #include <chrono> #include <deque> #include <iomanip> #include <iostream> #include <list> #include <map> #include <numeric> #include <set> #include <string> #include <unordered_map> #include <unordered_set> #include <utility> #include <vector> const int SIZE = 10000000; template <typename T> void measurePerformance(T& t, const std::string& cont){ std::cout << std::fixed << std::setprecision(10); auto begin= std::chrono::system_clock::now(); T t1(t); auto last= std::chrono::system_clock::now() - begin; std::cout << cont << std::endl; auto copyTime= std::chrono::duration<double>(last).count(); std::cout << " Copy: " << copyTime << " sec" << std::endl; begin= std::chrono::system_clock::now(); T t2(std::move(t)); last= std::chrono::system_clock::now() - begin; auto moveTime= std::chrono::duration<double>(last).count(); std::cout << " Move: " << moveTime << " sec" << std::endl; std::cout << std::setprecision(2); std::cout << " Ratio (copy time/move time): " << (copyTime/moveTime) << std::endl; std::cout << std::endl; } int main(){ std::cout << std::endl; { std::array<int,SIZE/1000> myArray; measurePerformance(myArray,"std::array<int,SIZE/1000>"); } { std::vector<int> myVec(SIZE); measurePerformance(myVec,"std::vector<int>(SIZE)"); } { std::deque<int>myDec(SIZE); measurePerformance(myDec,"std::deque<int>(SIZE)"); } { std::list<int>myList(SIZE); measurePerformance(myList,"std::list<int>(SIZE)"); } { std::forward_list<int>myForwardList(SIZE); measurePerformance(myForwardList,"std::forward_list<int>(SIZE)"); } { std::string myString(SIZE,' '); measurePerformance(myString,"std::string(SIZE,' ')"); } std::vector<int> tmpVec(SIZE); std::iota(tmpVec.begin(),tmpVec.end(),0); { std::set<int>mySet(tmpVec.begin(),tmpVec.end()); measurePerformance(mySet,"std::set<int>"); } { std::unordered_set<int>myUnorderedSet(tmpVec.begin(),tmpVec.end()); measurePerformance(myUnorderedSet,"std::unordered_set<int>"); } { std::map<int,int>myMap; for (auto i= 0; i <= SIZE; ++i) myMap[i]= i; measurePerformance(myMap,"std::map<int,int>"); } { std::unordered_map<int,int>myUnorderedMap; for (auto i= 0; i <= SIZE; ++i) myUnorderedMap[i]= i; measurePerformance(myUnorderedMap,"std::unordered_map<int,int>"); } } |
The idea of the program is to initialize the containers with 10 million elements. Of course, the initialization will happen with copy and move semantics. The performance measurement occurs in the function template measurePerformane (lines 21 – 44). The function takes as an argument the container and the name of the container. Thanks to the Chrono library I can measure how long the copy initialization (line 27) and the move initialization (line 34) take. Ultimately, I’m interested in the ratio between the copy and move semantics (line 40).
What’s happening in the main function? I create each container with its scope so that it will be automatically released. Therefore, myArray (line 51) will automatically be released and the end of its scope (line 53). Because the containers are quite big, releasing their memory is a must. I claimed that each container has 10 million elements. That will not hold for myArray. Because myArray will not be allocated on the heap, I must dramatically reduce its size. But now to the remaining containers. With std::vector, std::deque, std::list, and std::forward_list there are in lines 55 – 73 the remaining sequential containers. In lines 75 – 78 std::string follows. The rest are the associative containers. I have to pay attention to one characteristic of the associative container. To have unique keys and therefore the size 10 million, I use the numbers 0 to 9999999 as keys. The function std::iota does the job.
The numbers
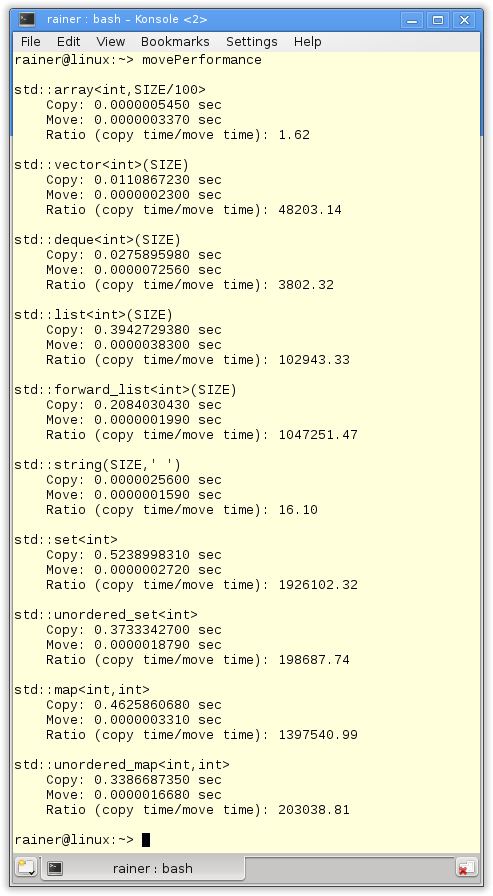
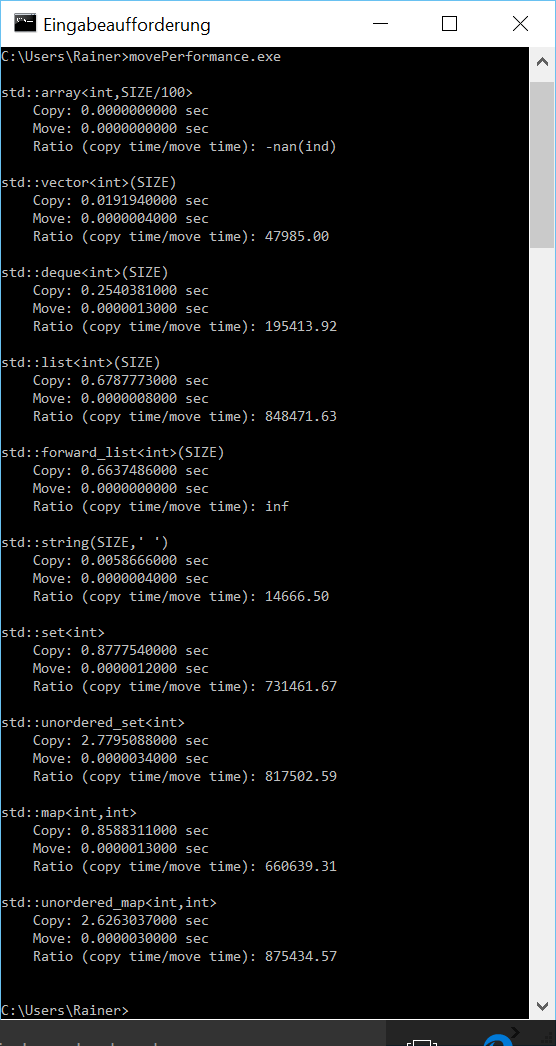
The results of std::array are not so meaningful. On the one hand, std::array is not so big; on the other hand, the time difference on Windows is not measurable with the clock std::system_clock.
What insight can I derive from the numbers?
- Sequential container: std::vector is the fastest container in case of copying or moving.
- Sequential versus associative container: Copying the sequential container on Linux and Windows is faster.
- Copy versus move semantics: The differences between the copy and move semantics are huge. That holds, in particular, true for the associative containers.
- std::string: The std::string on Linux behaves strangely. On the one hand, copying is very fast; on the other hand, moving is only 16 times faster than copying. The becomes even more strange if I compile and execute the program without optimization. I get the result on Linux that the move semantics is only 1.5 times faster than the copy semantics. But these numbers are in strong contradiction to the numbers on Windows. On Windows, the move semantic is 15000 times faster than the copy semantic.
The riddle around std::string
The performance difference between the copy and move semantics on Linux and Windows is quickly explained. My GCC implements the std::string according to copy-on-write (cow). This is not conformant to the C++11 standard. But cl.exe implements std::string according to the C++11 standard. I will get different numbers if I compile the program with GCC 6.1 and enable C++11. GCC’s std::string implementation is since 5.1 conformant to the C++11 standard.
Here are the numbers with the online compiler on en.cppreference.com.
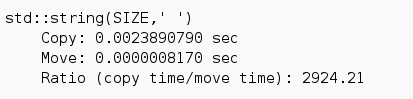
Now, there is a big difference between the copy and move semantics.
What’s next?
I hope that was the motivation for the move semantics. In the next post, I will pick two nice characteristics of the move semantic.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Phillip Diekmann, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org







Leave a Reply
Want to join the discussion?Feel free to contribute!