Thread-Safe Initialization of a Singleton
There are a lot of issues with the singleton pattern. I’m aware of that. But the singleton pattern is an ideal use case for a variable, which can only be initialized in a thread-safe way. From that point on, you can use it without synchronization. So in this post, I discuss different ways to initialize a singleton in a multithreading environment. You get the performance numbers and can reason about your use cases for the thread-safe initialization of a variable.
There are many different ways to initialize a singleton in C++11 in a thread-safe way. From a birds-eye, you can have guarantees from the C++ runtime, locks, or atomics. I’m totally curious about the performance implications.
My strategy
As a reference point for my performance measurement, I use a singleton object which I sequential access 40 million times. The first access will initialize the object. In contrast, the access from the multithreading program will be done by four threads. Here I’m only interested in the performance. The program will run on two real PCs. My Linux PC has four; my Windows PC has two cores. I compile the program with maximum and without optimization. To translate the program with maximum optimization, I have to use a volatile variable in the static method getInstance. If not, the compiler will optimize away my access to the singleton, and my program becomes too fast.
I have three questions in my mind:
- What is the relative performance of the different singleton implementations?
- Is there a significant difference between Linux (GCC) and Windows (cl.exe)?
- What’s the difference between the optimized and non-optimized versions?
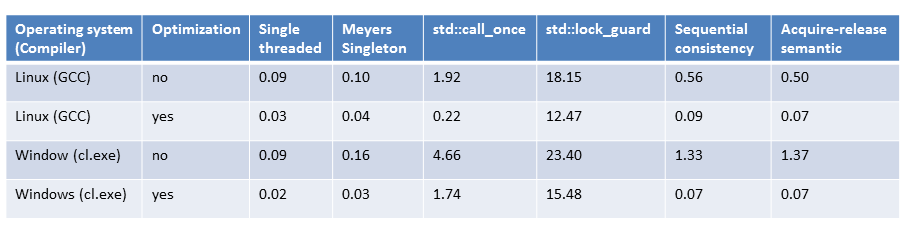
Finally, I collect all numbers in a table. The numbers are in seconds.
The reference values
The both compilers
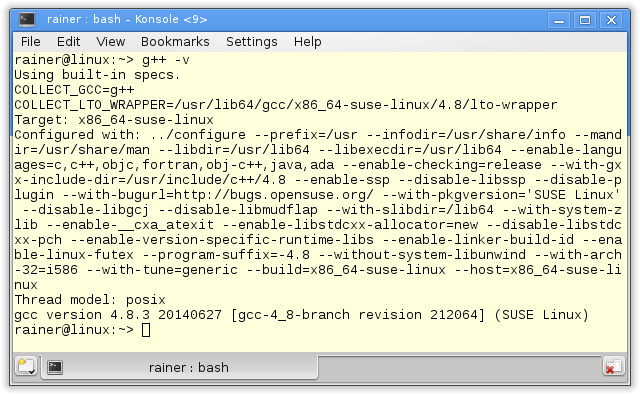
The command line gives you the details of the compiler Here are the gcc and the cl.exe.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Be part of my mentoring programs:
Do you want to stay informed: Subscribe.
The reference code
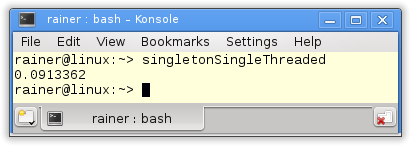
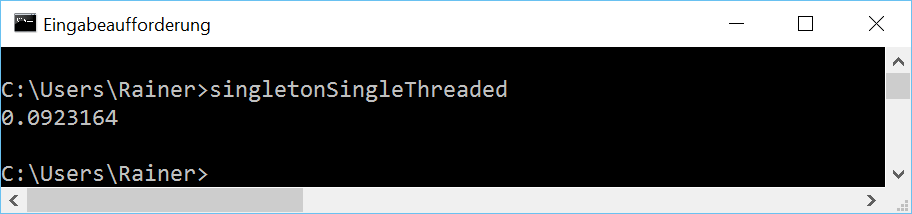
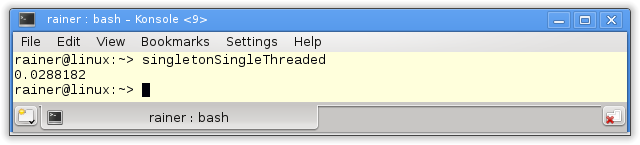
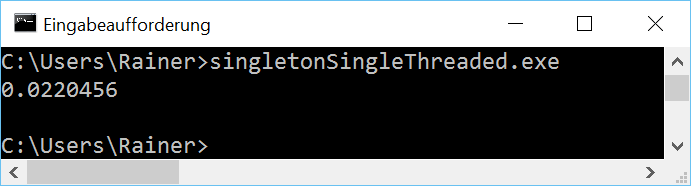
At first, the single-threaded case. Of course, without synchronization.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
// singletonSingleThreaded.cpp #include <chrono> #include <iostream> constexpr auto tenMill= 10000000; class MySingleton{ public: static MySingleton& getInstance(){ static MySingleton instance; // volatile int dummy{}; return instance; } private: MySingleton()= default; ~MySingleton()= default; MySingleton(const MySingleton&)= delete; MySingleton& operator=(const MySingleton&)= delete; }; int main(){ constexpr auto fourtyMill= 4* tenMill; auto begin= std::chrono::system_clock::now(); for ( size_t i= 0; i <= fourtyMill; ++i){ MySingleton::getInstance(); } auto end= std::chrono::system_clock::now() - begin; std::cout << std::chrono::duration<double>(end).count() << std::endl; } |
I use in the reference implementation the so-called Meyers Singleton. The elegance of this implementation is that the singleton object instance in line 11 is a static variable with block scope. Therefore, instance will exactly be initialized when the static method getInstance (lines 10 – 14) will be executed the first time. In line 14, the volatile variable dummy is commented out. When I translate the program with maximum optimization, that has to change, so the call MySingleton::getInstance() will not be optimized away.
Now the raw numbers on Linux and Windows.
Without optimization
Maximum Optimization
Guarantees of the C++ runtime
I already presented the details to the thread-safe initialization of variables in the post Thread-safe initialization of data.
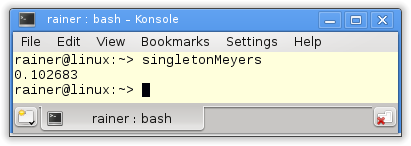
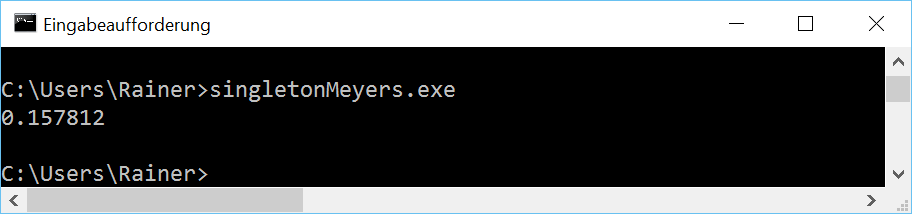
Meyers Singleton
The beauty of the Meyers Singleton in C++11 is that it’s automatically thread-safe. That is guaranteed by the standard: Static variables with block scope. The Meyers Singleton is a static variable with block scope, so we are done. It’s still left to rewrite the program for four threads.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
// singletonMeyers.cpp #include <chrono> #include <iostream> #include <future> constexpr auto tenMill= 10000000; class MySingleton{ public: static MySingleton& getInstance(){ static MySingleton instance; // volatile int dummy{}; return instance; } private: MySingleton()= default; ~MySingleton()= default; MySingleton(const MySingleton&)= delete; MySingleton& operator=(const MySingleton&)= delete; }; std::chrono::duration<double> getTime(){ auto begin= std::chrono::system_clock::now(); for ( size_t i= 0; i <= tenMill; ++i){ MySingleton::getInstance(); } return std::chrono::system_clock::now() - begin; }; int main(){ auto fut1= std::async(std::launch::async,getTime); auto fut2= std::async(std::launch::async,getTime); auto fut3= std::async(std::launch::async,getTime); auto fut4= std::async(std::launch::async,getTime); auto total= fut1.get() + fut2.get() + fut3.get() + fut4.get(); std::cout << total.count() << std::endl; } |
I use the singleton object in the function getTime (lines 24 – 32). The function is executed by the four promise in lines 36 – 39. The results of the associate futures are summed up in line 41. That’s all. Only the execution time is missing.
Without optimization
Maximum optimization
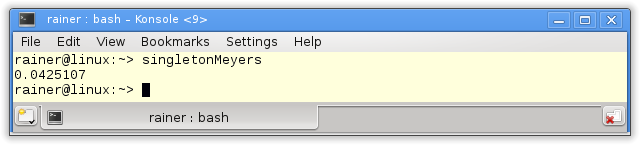
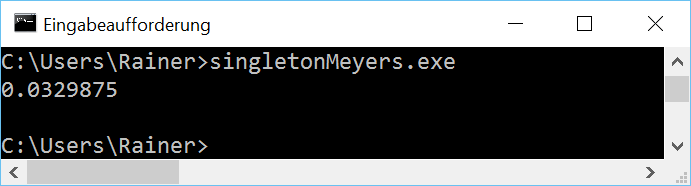
The next step is the function std::call_once in combination with the flag std::once_flag.
The function std::call_once and the flag std::once_flag
You can use the function std::call_once to register a callable executed exactly once. The flag std::call_once in the following implementation guarantees that the singleton will be thread-safe initialized.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
// singletonCallOnce.cpp #include <chrono> #include <iostream> #include <future> #include <mutex> #include <thread> constexpr auto tenMill= 10000000; class MySingleton{ public: static MySingleton& getInstance(){ std::call_once(initInstanceFlag, &MySingleton::initSingleton); // volatile int dummy{}; return *instance; } private: MySingleton()= default; ~MySingleton()= default; MySingleton(const MySingleton&)= delete; MySingleton& operator=(const MySingleton&)= delete; static MySingleton* instance; static std::once_flag initInstanceFlag; static void initSingleton(){ instance= new MySingleton; } }; MySingleton* MySingleton::instance= nullptr; std::once_flag MySingleton::initInstanceFlag; std::chrono::duration<double> getTime(){ auto begin= std::chrono::system_clock::now(); for ( size_t i= 0; i <= tenMill; ++i){ MySingleton::getInstance(); } return std::chrono::system_clock::now() - begin; }; int main(){ auto fut1= std::async(std::launch::async,getTime); auto fut2= std::async(std::launch::async,getTime); auto fut3= std::async(std::launch::async,getTime); auto fut4= std::async(std::launch::async,getTime); auto total= fut1.get() + fut2.get() + fut3.get() + fut4.get(); std::cout << total.count() << std::endl; } |
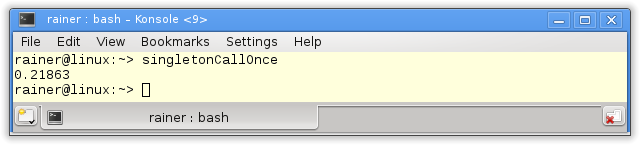
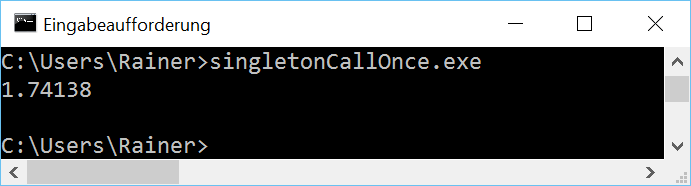
Here are the numbers.
Without optimization
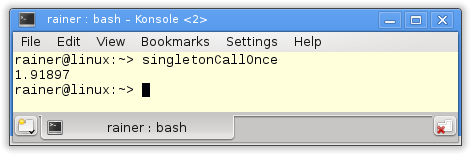
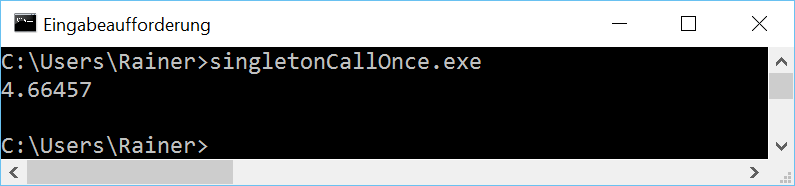
Maximum optimization
Of course, the most obvious way is it protects the singleton with a lock.
Lock
The mutex wrapped in a lock guarantees that the singleton will be thread-safe initialized.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
// singletonLock.cpp #include <chrono> #include <iostream> #include <future> #include <mutex> constexpr auto tenMill= 10000000; std::mutex myMutex; class MySingleton{ public: static MySingleton& getInstance(){ std::lock_guard<std::mutex> myLock(myMutex); if ( !instance ){ instance= new MySingleton(); } // volatile int dummy{}; return *instance; } private: MySingleton()= default; ~MySingleton()= default; MySingleton(const MySingleton&)= delete; MySingleton& operator=(const MySingleton&)= delete; static MySingleton* instance; }; MySingleton* MySingleton::instance= nullptr; std::chrono::duration<double> getTime(){ auto begin= std::chrono::system_clock::now(); for ( size_t i= 0; i <= tenMill; ++i){ MySingleton::getInstance(); } return std::chrono::system_clock::now() - begin; }; int main(){ auto fut1= std::async(std::launch::async,getTime); auto fut2= std::async(std::launch::async,getTime); auto fut3= std::async(std::launch::async,getTime); auto fut4= std::async(std::launch::async,getTime); auto total= fut1.get() + fut2.get() + fut3.get() + fut4.get(); std::cout << total.count() << std::endl; } |
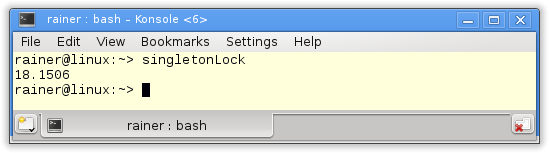
How fast is the classical thread-safe implementation of the singleton pattern?
Without optimization
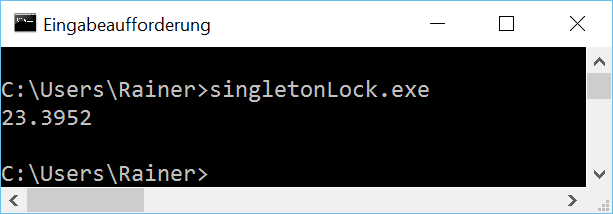
Maximum optimization
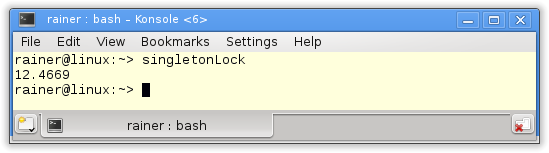
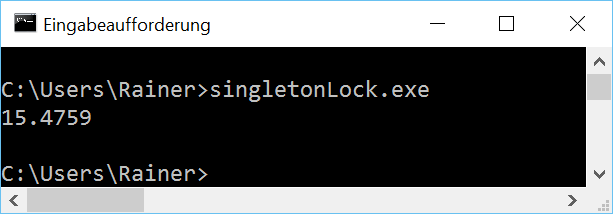
Not so fast. Atomics should make a difference.
Atomic variables
With atomic variables, my job becomes exceptionally challenging. Now I have to use the C++ memory model. I base my implementation on the well-known double-checked locking pattern.
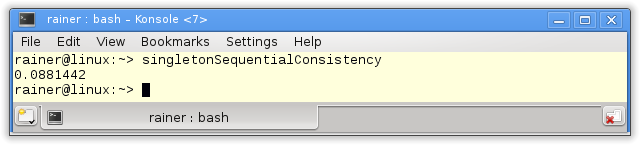
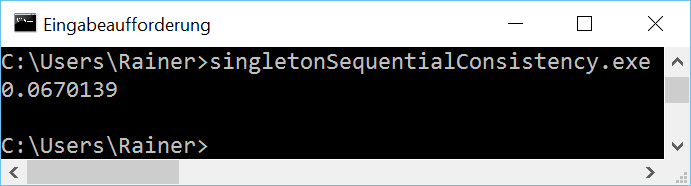
Sequential consistency
The handle to the singleton is atomic. Because I didn’t specify the C++ memory model, the default applies Sequential consistency.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
// singletonAcquireRelease.cpp #include <atomic> #include <iostream> #include <future> #include <mutex> #include <thread> constexpr auto tenMill= 10000000; class MySingleton{ public: static MySingleton* getInstance(){ MySingleton* sin= instance.load(); if ( !sin ){ std::lock_guard<std::mutex> myLock(myMutex); sin= instance.load(); if( !sin ){ sin= new MySingleton(); instance.store(sin); } } // volatile int dummy{}; return sin; } private: MySingleton()= default; ~MySingleton()= default; MySingleton(const MySingleton&)= delete; MySingleton& operator=(const MySingleton&)= delete; static std::atomic<MySingleton*> instance; static std::mutex myMutex; }; std::atomic<MySingleton*> MySingleton::instance; std::mutex MySingleton::myMutex; std::chrono::duration<double> getTime(){ auto begin= std::chrono::system_clock::now(); for ( size_t i= 0; i <= tenMill; ++i){ MySingleton::getInstance(); } return std::chrono::system_clock::now() - begin; }; int main(){ auto fut1= std::async(std::launch::async,getTime); auto fut2= std::async(std::launch::async,getTime); auto fut3= std::async(std::launch::async,getTime); auto fut4= std::async(std::launch::async,getTime); auto total= fut1.get() + fut2.get() + fut3.get() + fut4.get(); std::cout << total.count() << std::endl; } |
Now I’m curious.
Without optimization
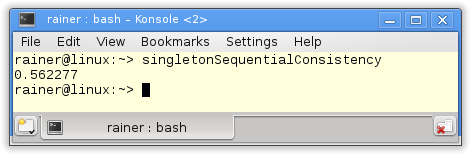
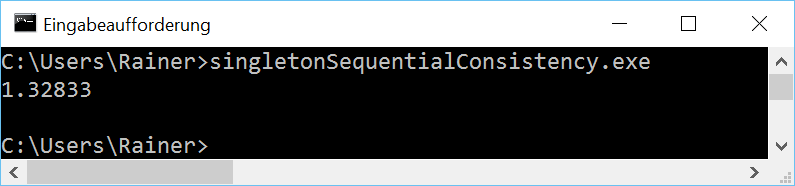
Maximum optimization
But we can do better. There is an additional optimization possibility.
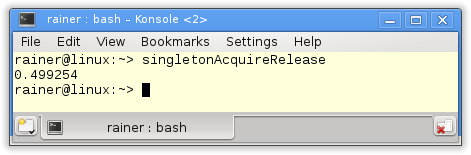
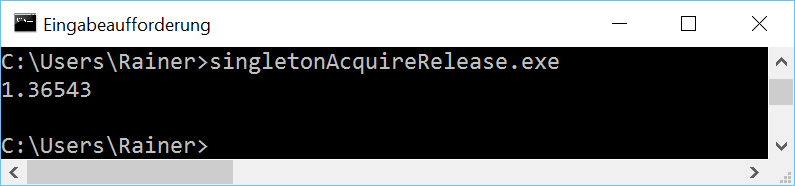
Acquire-release Semantic
The reading of the singleton (line 14) is an acquire operation, and the writing is a release operation (line 20). Because both operations occur on the same atomic I don’t need sequential consistency. The C++ standard guarantees that an acquire operation synchronizes with a release operation on the same atomic. These conditions hold in this case. Therefore, I can weaken the C++ memory model in lines 14 and 20. Acquire-release semantic is sufficient.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
// singletonAcquireRelease.cpp #include <atomic> #include <iostream> #include <future> #include <mutex> #include <thread> constexpr auto tenMill= 10000000; class MySingleton{ public: static MySingleton* getInstance(){ MySingleton* sin= instance.load(std::memory_order_acquire); if ( !sin ){ std::lock_guard<std::mutex> myLock(myMutex); sin= instance.load(std::memory_order_relaxed); if( !sin ){ sin= new MySingleton(); instance.store(sin,std::memory_order_release); } } // volatile int dummy{}; return sin; } private: MySingleton()= default; ~MySingleton()= default; MySingleton(const MySingleton&)= delete; MySingleton& operator=(const MySingleton&)= delete; static std::atomic<MySingleton*> instance; static std::mutex myMutex; }; std::atomic<MySingleton*> MySingleton::instance; std::mutex MySingleton::myMutex; std::chrono::duration<double> getTime(){ auto begin= std::chrono::system_clock::now(); for ( size_t i= 0; i <= tenMill; ++i){ MySingleton::getInstance(); } return std::chrono::system_clock::now() - begin; }; int main(){ auto fut1= std::async(std::launch::async,getTime); auto fut2= std::async(std::launch::async,getTime); auto fut3= std::async(std::launch::async,getTime); auto fut4= std::async(std::launch::async,getTime); auto total= fut1.get() + fut2.get() + fut3.get() + fut4.get(); std::cout << total.count() << std::endl; } |
The acquire-release semantic has a similar performance as the sequential consistency. That’s not surprising because on x86, both memory models are very similar. We would get different numbers on an ARMv7 or PowerPC architecture. You can read the details on Jeff Preshing’s blog Preshing on Programming.
Without optimization
Maximum optimization
 .
.
If I forget an import variant of the thread-safe singleton pattern, please let me know and send me the code. I will measure it and add the numbers to the comparison.
All numbers at one glance
Don’t take the numbers too seriously. I executed each program only once, and the executable is optimized for four cores on my two-core windows PC. But the numbers give a clear indication. The Meyers Singleton is the easiest to get and the fastest one. In particular, the lock-based implementation is by far the slowest one. The numbers are independent of the used platform.
But the numbers show more. Optimization counts. This statement is not totally accurate for the std::lock_guard based implementation of the singleton pattern.
What’s next?
I’m not so sure. This post is a translation of a german post I wrote half a year ago. My German post gets a lot of reaction. I’m not sure what will happen this time. A few days’ later, I’m sure. The next post will be about adding the elements of a vector. First, it takes in one thread.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Kris Kafka, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Phillip Diekmann, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, moon, Philipp Lenk, Hobsbawm, Charles-Jianye Chen, and Keith Jeffery.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Seminars
I’m happy to give online seminars or face-to-face seminars worldwide. Please call me if you have any questions.
Standard Seminars (English/German)
Here is a compilation of my standard seminars. These seminars are only meant to give you a first orientation.
- C++ – The Core Language
- C++ – The Standard Library
- C++ – Compact
- C++11 and C++14
- Concurrency with Modern C++
- Design Pattern and Architectural Pattern with C++
- Embedded Programming with Modern C++
- Generic Programming (Templates) with C++
- Clean Code with Modern C++
- C++20
Online Seminars (German)
- Clean Code: Best Practices für modernes C++ (21. Mai 2024 bis 23. Mai 2024)
- Embedded
Programmierung mit modernem C++ (2. Jul 2024 bis 4.
Jul 2024)
Contact Me
- Phone: +49 7472 917441
- Mobil:: +49 176 5506 5086
- Mail: schulung@ModernesCpp.de
- German Seminar Page: www.ModernesCpp.de
- Mentoring Page: www.ModernesCpp.org
Modernes C++ Mentoring,






Leave a Reply
Want to join the discussion?Feel free to contribute!