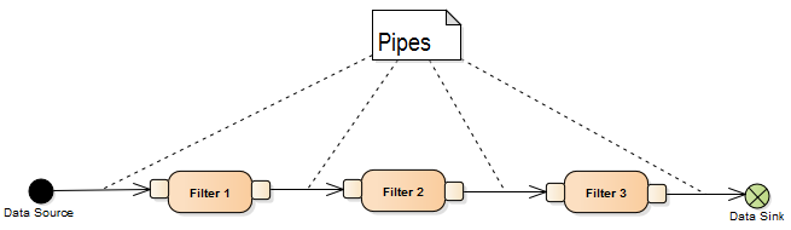
Pipes-and-Filters
The Pipes-and-Filters architecture pattern describes the structure of systems that process data streams.
The Pipes-and-Filters pattern is similar to the Layers Pattern. The idea of the Layers Pattern is to structure the system in layers so that higher layers are based on the services of lower layers. The Pipes-and-Filters naturally extend the Layers Pattern, using the layers as filters and the data flow as pipes.
Pipes-and-Filters
Purpose
- A system that processes data in several steps
- Each step processes its data independently from the other
Solution
- Divide the task into several processing steps
- Each processing step is the input for the next processing step
- The processing step is called a filter; the data channel between the filters is called a pipe
- The data comes from the data source and ends up in the data sink
Structure
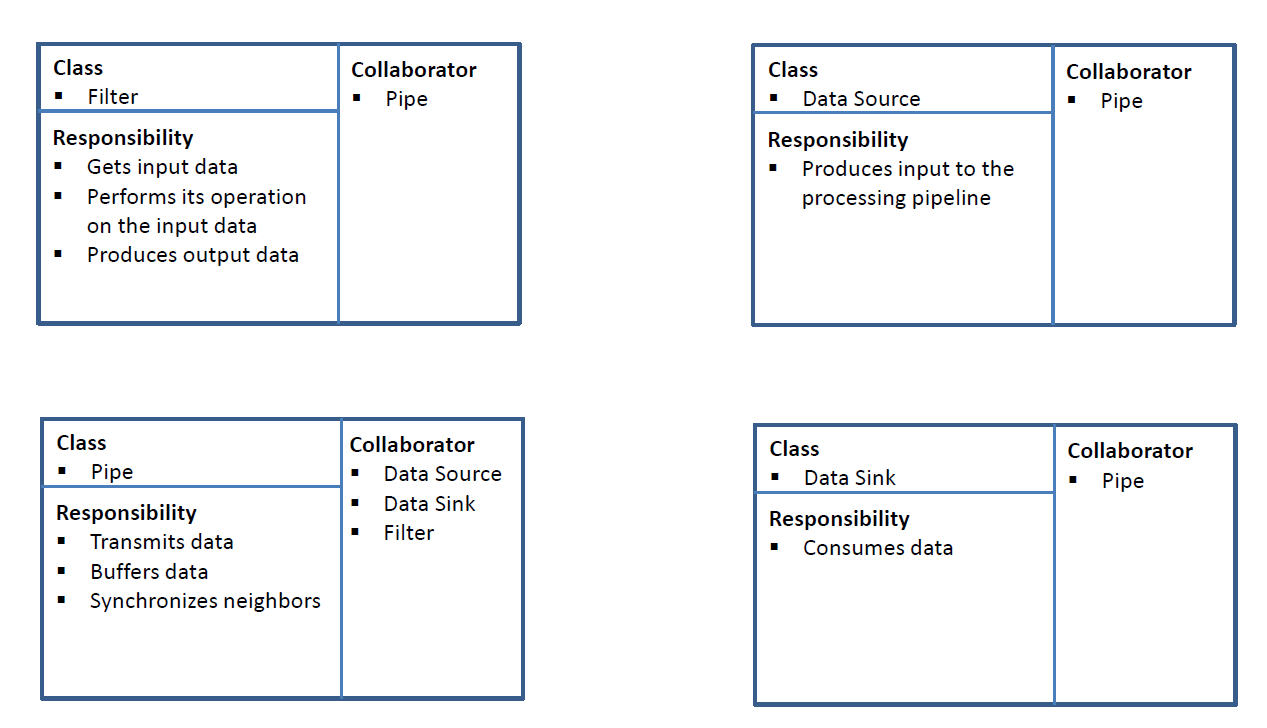
Filter- Gets input data
- Performs its operation on the input data
- Produces output data
Pipe- Transmits data
- Buffers data in a queue
- Synchronizes neighbors
Data Source- Produces input to the processing pipeline
Data Sink- Consumes data
The most interesting part of the Pipes-and-Filter is the data flow.
Data Flow
There are several ways to control the data flow.
Push Principle
- The filter is started by passing the data of the previous filter
- The (n-1)-th filter sends (write operation) data to the n-th filter
- The data source starts the data flow
Pull Principle
- The filter is started by requesting data from the previous filter
- The n-th filter requests data from the (n-1)-th filter
- The data sink starts the data flow
Mixed Push/Pull Principle
- The n-th filter requests data from the (n-1)-th filter and explicitly passes it to the (n+1)-th filter
- The n-th filter is the only active filter in the processing chain
- The n-th filter starts the data flow
Active Filters as Independent Processes
- Each filter is an independent process that reads data from the previous queue or writes data to the following queue
- The n-th filter can read data only after the (n-1)-th filter has written data to the connecting queue
- The n-th filter can write its data only after the (n+1)-th filter has read the connecting queue
- This structure is known as the Producer/Consumer
- Each filter can start the data flow
Example
The most prominent example of the Pipes-and-Filters Pattern is the UNIX Command Shell.
Unix Command Shell
-
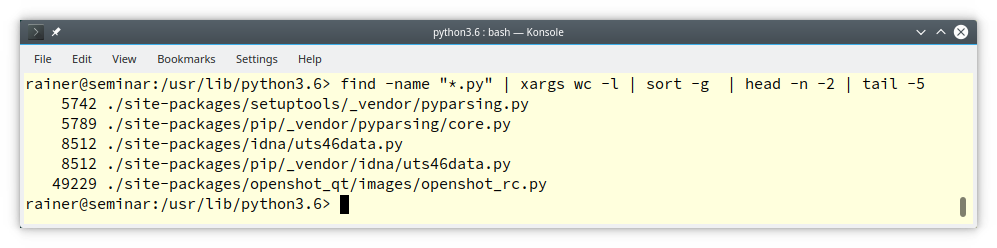
Find the five python files in my python3.6 installation that have the most lines:
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
Here are the steps of the pipeline:
- Find all files ending with py:
find -name "*.py" - Get from each file its number of lines:
xargs wc -l - Sort numerical:
sort -g - Remove the last two lines having irrelevant statistical information:
head -n -2 - Get the five last lines:
tail -5
Finally, here is the classic of command line processing using pipes from Douglas Mcllroy.
tr -cs A-Za-z '\n' | tr A-Z a-z | sort | uniq -c | sort -rn | sed ${1}q
If you want to know what this pipeline does, read the full story behind it in the article “More shell, less egg“.
Thanks to the ranges library in C++20, the Pipes-and-Filters Pattern is directly supported in C++.
Ranges
The following program firstTenPrimes.cpp displays the first ten primes starting with 1000.
// firstTenPrimes.cpp #include <iostream> #include <ranges> #include <vector> bool isPrime(int i) { for (int j = 2; j * j <= i; ++j){ if (i % j == 0) return false; } return true; } int main() { std::cout << '\n'; auto odd = [](int i){ return i % 2 == 1; }; auto vec = std::views::iota(1'000) | std::views::filter(odd) // (1) | std::views::filter(isPrime) // (2) | std::views::take(10) // (3) | std::ranges::to<std::vector>(); // (4) for (auto v: vec) std::cout << v << " "; }
The data source (std::views::iota(1'000)) creates the natural number, starting with 1000. First, the odd numbers are filtered out (line 1), and then the prime numbers (line 2). This pipeline stops after ten values (line 3) and pushes the elements onto the std::vector (line 4). The convenient function std::ranges::to creates a new range (line 4). This function is new with C++23. Therefore, I can only execute the code with the newest windows compiler on the compiler explorer.

Pros and Cons
I use in my following comparison the term universal interface. This means all filters speak the same language, such as xml or jason.
Pros
- When one filter pushes or pulls the data directly from its neighbor, no intermediate buffering of data is necessary
- An n-th filter implements the Layers Pattern and can, therefore, easily be replaced
- Filters, implementing the universal interface, can be reordered
- Each filter can work independently of the other and has not had to wait until the neighbored filter is done. This enables the optimal distribution of work between the filters.
- Filters can run in a distributed architecture. The pipes connect the remote entities. The pipes can also split or synchronize the data flow. Pipes-and-Filters are heavily used in distributed or concurrent architectures and provide excellent performance and scalability opportunities.
Cons
- The parallel processing of data may be inefficient due to communication, serialization, and synchronization overhead
- A filter such as a sort needs the entire data
- If the processing power of the filters is not homogenous, you need big queues between them
- To support the universal interface, that data must be formatted between the filters
- The most complicated part of this pattern is error handling. When the Pipes-and-Filters architecture crashes during the data processing, you have data that is not partially and fully processed. Now, you have a few options:
- Start the process once more if you have the original data.
- Use only the fully processed data.
- Introduce markers in your input data. You start the process based on the markers when your system crashes.
What’s Next?
The Broker structures distributed software systems that interact with remote service invocations. It is responsible for coordinating the communication, its results, and exceptions. In my next post, I will dive deeper into the architectural pattern Broker.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org




Leave a Reply
Want to join the discussion?Feel free to contribute!