C++ Memory Model
Since C++11, C++ has a memory model. It is the foundation for multithreading. Without it, multithreading is not well defined.
The C++ memory model consists of two aspects. On the one hand, the memory model’s enormous complexity often contradicts our intuition. On the other hand, the memory model helps to get a deeper insight into the multithreading challenges.
The contract
In the first approach, the C++ memory model defines a contract. This contract is established between the programmer and the system. The system consists of the compiler, which compiles the program into assembler instructions, the processor, which performs the assembler instructions, and the different caches, which stores the state of the program. The contract requires the programmer to obey specific rules and gives the system the full power to optimize the program as far as no rules are broken. In the good case, the result is a well-defined program that is maximally optimized. Precisely speaking, there is not only a single contract but a fine-grained set of contracts. Or to say it differently. The weaker the rules the programmer has to follow, the more potential there is for the system to generate a highly optimized executable.
The rule of thumb is relatively easy. The stronger the contract, the fewer liberties for the system to generate an optimized executable. Sadly, the other way around will not work. If the programmer uses an extremely weak contract or memory model, there are a lot of optimization choices. But the program is only manageable by a few world wide known experts.
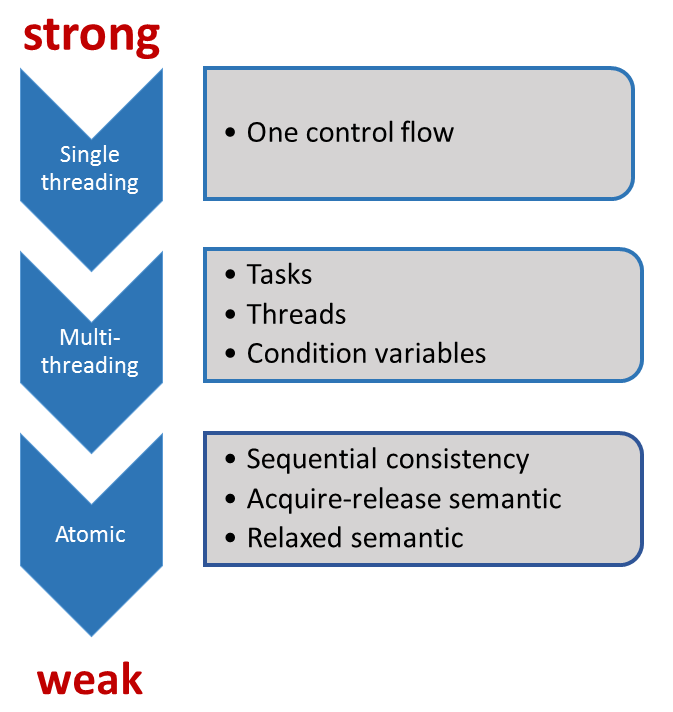
There are three levels of the contract in C++11.
Before C++11, there was only one contract. C++ was not aware of the existence of multithreading or atomics. The system only knows one control flow, and there were restricted opportunities to optimize the executable. The critical point of the system was to keep the illusion for the programmer that the observed behavior of the program corresponds to the sequence of the instructions in the source code. Of course, there was no memory model. Instead of that, there was the concept of a sequence point. Sequence points are points in the program at which the effects of all instructions before must be observable. The start or the end of the execution of a function are sequence points. But if you invoke a function with two arguments, the C++ standard does not guarantee which arguments will be evaluated at first. So the behavior is unspecified. The reason is straightforward. The comma operator is no sequence point. That will not change in C++11.
But with C++, all will change. C++11 is the first time aware of multiple threads. The reason for the well-defined behavior of threads is the C++ memory model. The Java memory model inspires the C++ memory model, but the C++ one goes – as ever – a few steps further. But that will be the topic of the following posts. So the programmer has to obey a few rules in dealing with shared variables to get a well-defined program. The program is undefined if there exists at least one data race. As mentioned, you must be aware of data races if your threads share mutable data. So tasks are a lot easier to use than threads or condition variables.
With atomics, we enter the domain of the experts. This will become more evident as we weaken the C++ memory model. Often, we speak about lock-free programming when we use atomics. I spoke in the posts about the weak and strong rules. Indeed, the sequential consistency is called the strong memory model, the relaxed semantic weak memory model.
The meat of the contract
The contract between the programmer and the system consists of three parts:
- Atomic operations: Operations that will be executed without interruption.
- The partial order of operations: Sequence of operations, which can not be changed.
- Visible effects of operations: Guarantees when an operation on shared variables will be visible in another thread.
The foundation of the contract are operations on atomics. These operations have two characteristics. They are atomic, creating synchronization and order constraints on the program execution. These synchronizations and order constraints will often also hold for not atomic operations. On the one hand, an atomic operation is always atomic, but on the other hand, you can tailor the synchronizations and order constraints to your needs.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
Back to the big picture
The more we weaken the memory model, the more our focus will change.
- More optimization potential for the system
- The number of control flows of the program increases exponentially
- Domain for the experts
- Break of the intuition
- Area for micro optimization
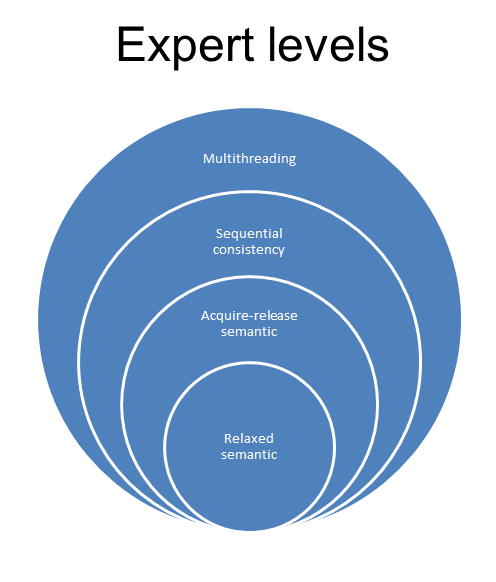
To make multithreading, we should be an expert. To deal with atomics (sequential consistency), we should open the door to the next expertise level. And you know, what will happen when we talk about the acquire-release or relaxed semantic? We’ll go each time one step higher to the next expertise level.
What’s next?
In the next post, I dive deeper into the C++ memory model. So, the following posts will be about lock-free programming. On my journey, I will talk about atomics and its operations. In case we are done with the basics, the different levels of the memory model will follow. The starting point will be the straightforward sequential consistency, the acquire-release semantic will follow, and the not-so-intuitive relaxed semantic will be the endpoint. The following post is about the default behavior of atomic operations: Sequential consistency. (Proofreader Alexey Elymanov)
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Phillip Diekmann, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org





Leave a Reply
Want to join the discussion?Feel free to contribute!