C++ Core Guidelines: Rules for Concurrency and Parallelism
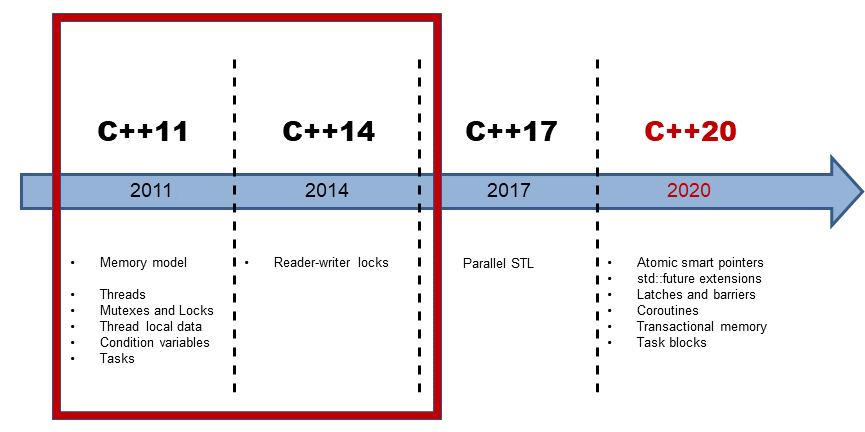
C++11 is the first C++ standard that deals with concurrency. The basic building block for concurrency is a thread; therefore, most rules are explicitly about threads. This changed dramatically with C++17.
With C++17 we got the Standard Template Library (STL) parallel algorithms. That means, most of the algorithms of the STL can be executed sequential, parallel, or vectorized. For the curious reader: I have already written two posts to the parallel STL. The post Parallel Algorithms of the Standard Template Library explains the execution policy in which you can run an existing algorithm sequentially, parallel, or parallel and vectorize. C++17 also gave new algorithms meant to run in parallel or vectorized. Here are the details: C++17: New Parallel Algorithms of the Standard Template Library.
The concurrency story in C++ goes on. With C++20, we can hope for extended futures, coroutines, transactions, and more. From the bird’s eye view, the concurrency facilities of C++11 and C++14 are only the implementation details on which the higher abstraction of C++17 and C++20 are based. Here is a series of posts about the concurrent future in C++20.
Said that the rules are mainly about threads because neither GCC nor Clang or MSVC has fully implemented the parallel algorithms of the STL. Best practices cannot be written to features that are not available (parallel STL) or even not standardized.
This is the first rule to remember when you read the rules. These rules are about available multithreading in C++11 and C++14. The second rule to keep in mind is that multithreading is very challenging. This means the rules want to give guidance to the novice and not to the experts in this domain. The rules of the memory model will follow in the future.
Now, let’s start and dive into the first rule.
CP.1: Assume that your code will run as part of a multi-threaded program
I was astonished when I read this rule the first time. Why should I optimize for the special case? To make it clear, this rule is mainly about code that is used in libraries, not in the application. And the experience shows that library code is often reused. This means you maybe optimize for the general case, which is fine.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
To make the point of the rule clear, here is a small example.
double cached_computation(double x) { static double cached_x = 0.0; // (1) static double cached_result = COMPUTATION_OF_ZERO; // (2) double result; if (cached_x == x) // (1) return cached_result; // (2) result = computation(x); cached_x = x; // (1) cached_result = result; // (2) return result; }
The function cached_computation is fine if it runs in a single-threaded environment. This will not hold for a multithreading environment because the static variables cached_x (1) and cached_result (2) can be used simultaneously by many threads, and they are modified during their usage. The C++11 standard adds multithreading semantics to static variables with block scope such as cached_x and cached_result. Static variables with block scope are initialized in C++11 in a thread-safe way.
This is fine but will not help in our case. We will get a data race if we invoke cached_computation simultaneously from many threads. The notion of a data race is essential in multithreading in C++; therefore, let me write about it.
A data race is a situation, in which at least two threads access a shared variable simultaneously. At least one thread tries to modify the variable.
The rest is quite simple. If you have a data race in your program, your program has undefined behavior. Undefined behavior means you can not reason anymore about your program because all can happen. I mean all. In my seminars, I often say: If your program has undefined behavior, it has catch-fire semantics. Even your computer can catch fire.
If you read the definition of data race quite carefully, you will notice that a shared mutable state is necessary for having a data race. Here is a picture to make this observation quite obvious.
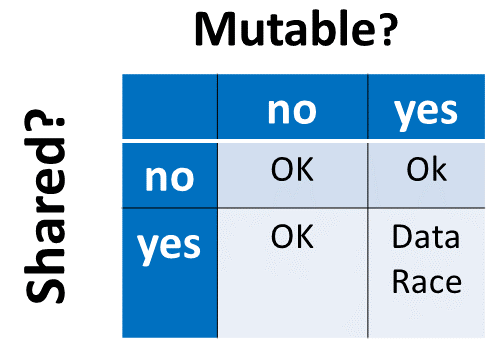
So, what can you do to get rid of the data race? Making the static variables cached_x (1) and cached_result (2) immutable (const) makes no sense. This means both static should not be shared. Here are a few ways to achieve this.
- Protect both static by their own lock.
- Use one lock to protect the entire critical region.
- Protect the call to the function cached_computation by a lock.
- Make both static thread_local. tread_local guarantees that each thread gets its variable cached_x and cached_result. Such as, a static variable is bound to the lifetime of the main thread, and a thread_local variable is bound to the lifetime of its thread.
Here are variations 1, 2, 3, and 4.
std::mutex m_x; std::mutex m_result; double cached_computation(double x){ // (1) static double cached_x = 0.0; static double cached_result = COMPUTATION_OF_ZERO; double result; { std::scoped_lock(m_x, m_result); if (cached_x == x) return cached_result; } result = computation(x); { std::lock_guard<std::mutex> lck(m_x); cached_x = x; } { std::lock_guard<std::mutex> lck(m_result); cached_result = result; } return result; } std::mutex m; double cached_computation(double x){ // (2) static double cached_x = 0.0; static double cached_result = COMPUTATION_OF_ZERO; double result; { std::lock_guard<std::mutex> lck(m); if (cached_x == x) return cached_result; result = computation(x); cached_x = x; cached_result = result; } return result; } std::mutex cachedComputationMutex; // (3) { std::lock_guard<std::mutex> lck(cachedComputationMutex); auto cached = cached_computation(3.33); } double cached_computation(double x){ // (4) thread_local double cached_x = 0.0; thread_local double cached_result = COMPUTATION_OF_ZERO; double result; if (cached_x == x) return cached_result; result = computation(x); cached_x = x; cached_result = result; return result; }
First, the C++11 standard guarantees that static variables are initialized in a thread-safe way; therefore, I don’t have to protect their initialization in all programs.
- This version is tricky because I have to acquire both locks in an atomic step. C++17 supports std::scoped_lock, which can lock an arbitrary number of mutexes in an atomic step. In C++11, you have to use instead of a std::unqiue_lock in combination with the function std::lock. My previous post Prefer Locks to Mutexes provides you with more details. This solution has a race condition on cached_x and cached_result because they must be accessed atomically.
- Version 2 uses a more coarse-grained locking. Usually, you should not use coarse-grained locks such as in the version but instead use fine-grained locking, but in this use case, it may be fine.
- This is the most coarse-grained solution because the entire function is locked. Of course, the downside is that the user of the function is responsible for the synchronization. In general, that is a bad idea.
- Just make the static variables thread_local, and you are done
In the end, it is a question of performance and your users. Therefore try each variation, measure, and think about the people who should use and maintain your code.
What’s next?
This post was just the starting point through a long journey of rules to concurrency in C++. In the next post, I will take about threads and shared state.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org







Leave a Reply
Want to join the discussion?Feel free to contribute!