Transactional Memory
Transactional memory is based on the idea of a transaction from the database theory. Transactional memory shall make the handling of threads a lot easier. That is for two reasons. Data races and deadlocks disappear. Transactions are composable.
A transaction is an action that has the properties Atomicity, Consistency, Isolation, and Durability (ACID). Except for the durability, all properties hold for transactional memory in C++; therefore, only three short questions are left.
ACI(D)
What means atomicity, consistency, and isolation mean for an atomic block consisting of some statements?
atomic{
statement1;
statement2;
statement3;
}
- Atomicity: Either all or no statement of the block is performed.
- Consistency: The system is always in a consistent state. All transactions build a total order.
- Isolation: Each transaction runs in total isolation from the other transactions.
How are these properties guaranteed? A transaction remembers its initial state. Then the transaction will be performed without synchronization. If a conflict happens during execution, the transaction will be interrupted and put to its initial state. This rollback causes the transaction will be executed once more. If the initial state of the transaction even holds at the end, the transaction will be committed.
A transaction is a kind of speculative activity that is only committed if the initial state holds. It is in contrast to a mutex, an optimistic approach. A transaction is performed without synchronization. It will only be published if no conflict with its initial state happens. A mutex is a pessimistic approach. At first, the mutex ensures that no other thread can enter the critical region. The thread will enter the critical region only if it is the exclusive owner of the mutex, and hence, all other threads are blocked.
C++ supports transactional memory in two flavors: synchronized blocks and atomic blocks.
Transactional Memory
Up to now, I only wrote about transactions. No, I will write more specifically about synchronized blocks and atomic blocks. Both can be encapsulated in the other. Specifically, synchronized blocks are not atomic blocks because they can execute transaction-unsafe code. This may be code like the output to the console, which can not be made undone. This is the reason why synchronized blocks are often called relaxed.
Synchronized Blocks
Synchronized blocks behave as a global lock that protects them. This means all synchronized blocks obey a total order; therefore, all changes to a synchronized block are available in the next synchronized block. There is a synchronize-with relation between the synchronized blocks. Because synchronized blocks behave as a global lock that protects them, they can not cause a deadlock. While a classical lock protects a memory area from explicit threads, the global lock of a synchronized block protects from all threads. That is the reason why the following program is well-defined:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
// synchronized.cpp #include <iostream> #include <vector> #include <thread> int i= 0; void increment(){ synchronized{ std::cout << ++i << " ,"; } } int main(){ std::cout << std::endl; std::vector<std::thread> vecSyn(10); for(auto& thr: vecSyn) thr = std::thread([]{ for(int n = 0; n < 10; ++n) increment(); }); for(auto& thr: vecSyn) thr.join(); std::cout << "\n\n"; } |
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
Although variable i in line 7 is a global variable and the operations in the synchronized block is transaction-unsafe, the program is well-defined. The access to i and std::cout happens in total order. That is due to the synchronized block.
The output of the program is not so thrilling. The values for i are written in an increasing sequence, separated by a comma, only for completeness.
What about data races? You can have them with synchronized blocks. Only a minor modification is necessary.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
// nonsynchronized.cpp #include <chrono> #include <iostream> #include <vector> #include <thread> using namespace std::chrono_literals; int i= 0; void increment(){ synchronized{ std::cout << ++i << " ,"; std::this_thread::sleep_for(1ns); } } int main(){ std::cout << std::endl; std::vector<std::thread> vecSyn(10); std::vector<std::thread> vecUnsyn(10); for(auto& thr: vecSyn) thr = std::thread([]{ for(int n = 0; n < 10; ++n) increment(); }); for(auto& thr: vecUnsyn) thr = std::thread([]{ for(int n = 0; n < 10; ++n) std::cout << ++i << " ,"; }); for(auto& thr: vecSyn) thr.join(); for(auto& thr: vecUnsyn) thr.join(); std::cout << "\n\n"; } |
To observe the data race, I let the synchronized block sleep for a nanosecond (line 15). At the same time, I access std::cout without using a synchronized block (line 29); therefore, I launch ten threads that increment the global variable i. The output shows the issue.
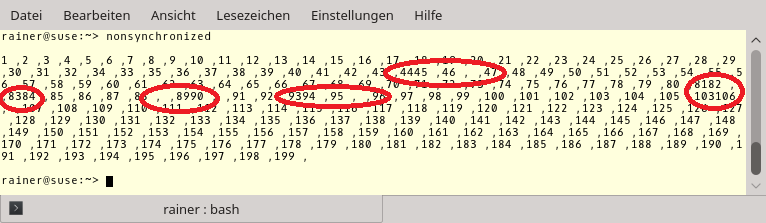
I put red circles around the issues in the output. These are the spots at which at least two threads use std::cout simultaneously. The C++11 standard guarantees that the characters will be written in an atomic way that is only an optical issue. But what is worse is that the variable i is written by at least two threads. This is a data race. Therefore the program has undefined behavior. If you look carefully at the output of the program you see that 103 is written twice.
The total order of synchronized blocks also holds for atomic blocks.
Atomic Blocks
You can execute transaction-unsafe code in a synchronized block but not an atomic one. Atomic blocks are available in the forms: atomic_noexcept, atomic_commit, and atomic_cancel. The suffixes _noexcept, _commit, and _cancel define how an atomic block should manage an exception.
- atomic_noexcept: If an exception throws, std::abort will be called, and the program aborts.
- atomic_cancel: In the default case, std::abort is called. That will not hold if a transaction-safe exception throws that is responsible for the ending of the transaction. In this case, the transaction will be canceled, put to its initial state, and the exception will be thrown.
- atomic_commit: The transaction will be committed normally if an exception is thrown.
transaction-safe exceptions: std::bad_alloc, std::bad_array_length, std::bad_array_new_length, std::bad_cast, std::bad_typeid, std::bad_exception, std::exception, and all exceptions that are derived from them are transaction-safe.
transaction_safe versus transaction_unsafe Code
You can declare a function as transaction_safe or attach the transaction_unsafe attribute to it.
int transactionSafeFunction() transaction_safe; [[transaction_unsafe]] int transactionUnsafeFunction();
transaction_safe is part of the type of a function. But what does transaction_safe mean? A transaction_safe function is, according to the proposal N4265, a function that has a transaction_safe definition. This holds if the following properties do not apply to its definition.
- It has a volatile parameter or a volatile variable.
- It has transaction-unsafe statements.
- If the function uses a constructor or destructor of a class in its body with a volatile non-static member.
Of course, this definition of transaction_safe is insufficient because it uses transaction_unsafe. You can read proposal N4265 and get the answer to what transaction_unsafe means.
What’s next?
The next post is about the fork-join paradigm. To be specific, it’s about task blocks.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org






Leave a Reply
Want to join the discussion?Feel free to contribute!