
The Regular Expression Library
My original plan was to write about the rules of the C++ Core Guidelines for the regex and chrono library, but besides the subsection title, no content is available. I already wrote a few posts about time functionality. So I’m done. Today, I fill the gap and write about the regex library.

Okay, here are my rules for regular expressions.
Only use a Regular Expression if you have to
Regular expressions are powerful but also sometimes expensive and complicated machinery to work with text. When the interface of a std::string or the algorithms of the Standard Template Library can do the job, use them.
Okay, but when should you use regular expressions? Here are the typical use cases.
Use-Case for Regular Expressions
- Check if a text matches a text pattern: std::regex_match
- Search for a text pattern in a text: std::regex_search
- Replace a text pattern with a text: std::regex_replace
- Iterate through all text patterns in a text: std::regex_iterator and std::regex_token_iterator
I hope you noticed it. The operations work on text patterns and not on text.
First, you should use raw strings to write your regular expression.
Use Raw Strings for Regular Expressions
First of all, for simplicity purposes, I will break the previous rule.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
The regular expression for the C++ text is quite ugly: C\\+\\+. You have to use two backslashes for each + sign. First, the + sign is a unique character in a regular expression. Second, the backslash is a special character in a string. Therefore one backslash escapes the + sign; the other backslash escapes the backslash.
By using a raw string literal, the second backslash is not necessary anymore because the backslash is not interpreted in the string.
The following short example may not convince you.
std::string regExpr("C\\+\\+"); std::string regExprRaw(R"(C\+\+)");
Both strings stand for regular expression, which matches the text C++. In particular, the raw string R”(C\+\+) is quite ugly to read. R”(Raw String)” delimits the raw string. By the way, regular expressions and path names on windows “C:\temp\newFile.txt” are typical use cases for raw strings.
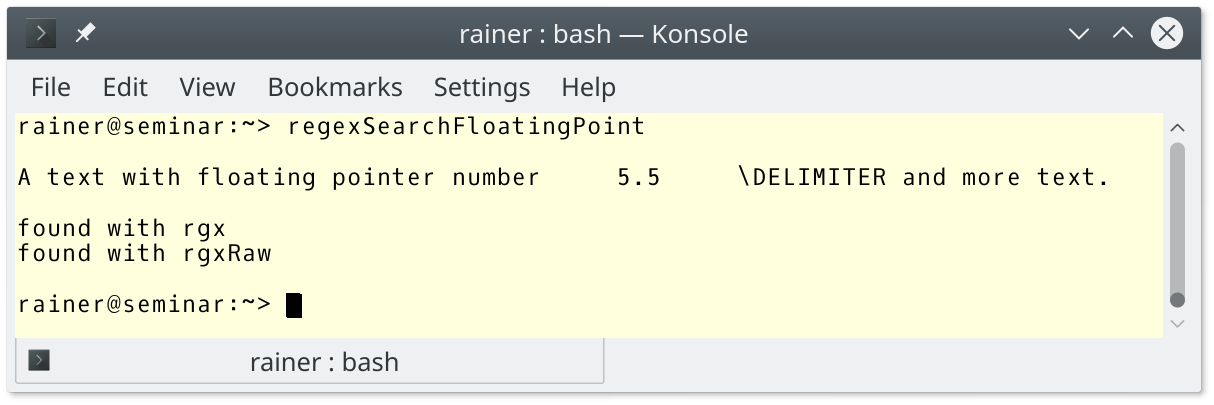
Imagine you want to search for a floating-point number in a text, which you identify by the following sequence of signs: Tabulator FloatingPointNumber Tabulator \\DELIMITER. Here is a concrete example for this pattern: “\t5.5\t\\DELIMITER“.
The following program uses a regular expression encoded in a string and a raw string to match this pattern.
// regexSearchFloatingPoint.cpp #include <regex> #include <iostream> #include <string> int main(){ std::cout << std::endl; std::string text = "A text with floating pointer number \t5.5\t\\DELIMITER and more text."; std::cout << text << std::endl; std::cout << std::endl; std::regex rgx("\\t[0-9]+\\.[0-9]+\\t\\\\DELIMITER"); // (1) std::regex rgxRaw(R"(\t[0-9]+\.[0-9]+\t\\DELIMITER)"); // (2) if (std::regex_search(text, rgx)) std::cout << "found with rgx" << std::endl; if (std::regex_search(text, rgxRaw)) std::cout << "found with rgxRaw" << std::endl; std::cout << std::endl; }
The regular expression rgx(“\\t[0-9]+\\.[0-9]+\\t\\\\DELIMITER”) is pretty ugly. To find n “\“-symbols (line 1), you have to write 2 * n “\”-symbols. In contrast, using a raw string to define a regular expression makes it possible to express the pattern you are looking for directly in the regular expression: rgxRaw(R”(\t[0-9]+\.[0-9]+\t\\DELIMITER)”) (line 2). The subexpression [0-9]+\.[0-9]+ of the regular expression stands for a floating point number: at least one number [0-9]+ followed by a dot \. followed by at least one number [0-9]+.
Just for completeness, the output of the program.
Honestly, this example was relatively simple. Most of the time, you want to analyze your match result.
For further analysis, use your match_result
Using a regular expression typically consists of three steps. This holds for std::regex_search, and std::regex_match.
- Define the regular expression.
- Store the result of the search.
- Analyze the result.
Let’s see what that means—this time I want to find the first e-mail address in a text. The following regular expression (RFC 5322 Official Standard) for an e-mail address finds not all e-mail addresses because they are very irregular.
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[az0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x2\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*") @(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])
For readability, I made a line break in the regular expression. The first line matches the local part, and the second line the domain part of the e-mail address. My program uses a more straightforward regular expression for matching an e-mail address. It’s not perfect, but it will do its job. Additionally, I want to match the local part and the domain part of my e-mail address.
Here we are:
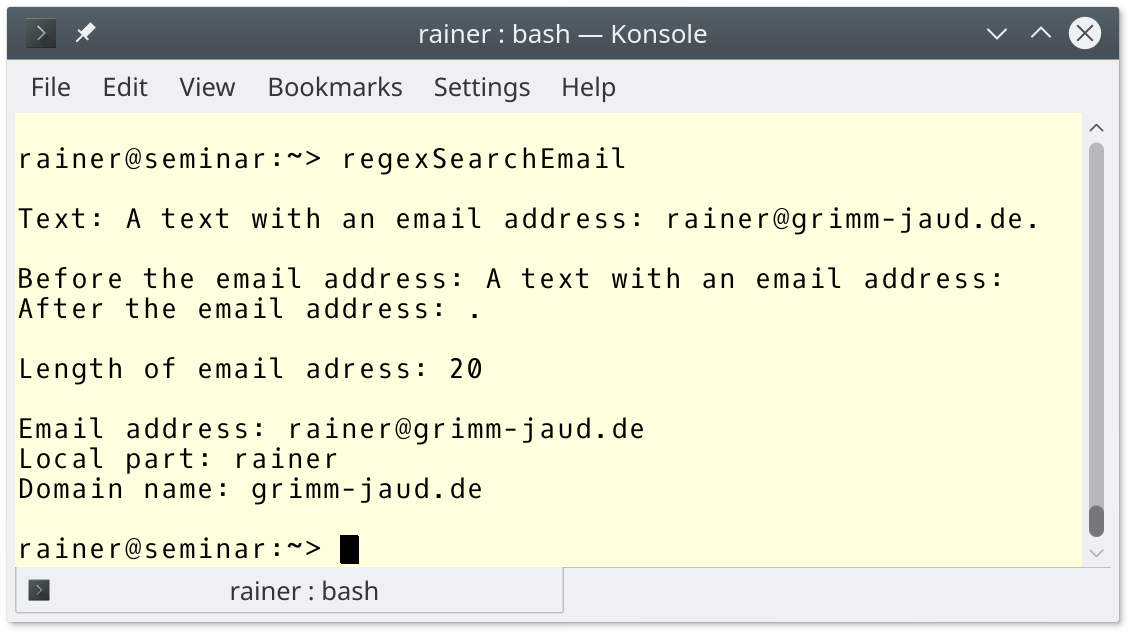
// regexSearchEmail.cpp #include <regex> #include <iostream> #include <string> int main(){ std::cout << std::endl; std::string emailText = "A text with an email address: rainer@grimm-jaud.de."; // (1) std::string regExprStr(R"(([\w.%+-]+)@([\w.-]+\.[a-zA-Z]{2,4}))"); std::regex rgx(regExprStr); // (2) std::smatch smatch; if (std::regex_search(emailText, smatch, rgx)){ // (3) std::cout << "Text: " << emailText << std::endl; std::cout << std::endl; std::cout << "Before the email address: " << smatch.prefix() << std::endl; std::cout << "After the email address: " << smatch.suffix() << std::endl; std::cout << std::endl; std::cout << "Length of email adress: " << smatch.length() << std::endl; std::cout << std::endl; std::cout << "Email address: " << smatch[0] << std::endl; // (6) std::cout << "Local part: " << smatch[1] << std::endl; // (4) std::cout << "Domain name: " << smatch[2] << std::endl; // (5) } std::cout << std::endl; }
Lines 1, 2, and 3 begin the three typical steps of using a regular expression. The regular expression in line 2 needs a few additional words.
Here it is:([\w.%+-]+)@([\w.-]+\.[a-zA-Z]{2,4})
- [\w.%+-]+: At least one of the following characters: “\w”, “.”, “%”, “+”, or “-“. “\w” stands for a word character.
- [\w.-]+\.[a-zA-Z]{2,4}: At least one of a “\w”, “.”, “-“, followed by a dot “.”, followed by 2 – 4 characters from the range a-z or A-Z.
- (…)@(…): The round braces stand for a capture group. They allow you to identify a sub match in a match. The first capture (line 4) group is the local part of an address. The second capture group (line 5) is the domain part of the e-mail address. You can address the match with the 0th capture group (line 6).
The output of the program shows a detailed analysis.
What’s next?
I’m not done. There is more to write about regular expressions in my next post. I write about various types of text and iterate through all matches.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org





Leave a Reply
Want to join the discussion?Feel free to contribute!