
C++ Core Guidelines: When RAII breaks
Before I write about the very popular RAII idiom in C++, I want to present you with a trick, which is often quite handy, when you repeatedly search for a text pattern: use negative search.

Often, the text patterns or tokens, you are looking for, are following a repetitive structure. Here, the negative search comes into play.
Use Negative Search if applicable
The general idea is easy to explain. You define a complicated regular expression to search for tokens. The tokens are often separated by delimiters such as colons, commas, spaces, and so on. In this case, it is easier to search for the delimiters, and the tokens you are interested in are just the text between the delimiters. Let’s see what I mean.
// regexTokenIterator.cpp #include <iostream> #include <string> #include <regex> #include <vector> std::vector<std::string> splitAt(const std::string &text, // (6) const std::regex ®) { std::sregex_token_iterator hitIt(text.begin(), text.end(), reg, -1); const std::sregex_token_iterator hitEnd; std::vector<std::string> resVec; for (; hitIt != hitEnd; ++hitIt) resVec.push_back(hitIt->str()); return resVec; } int main() { std::cout << std::endl; const std::string text("3,-1000,4.5,-10.5,5e10,2e-5"); // (1) const std::regex regNumber( R"([-+]?([0-9]+\.?[0-9]*|\.[0-9]+)([eE][-+]?[0-9]+)?)"); // (2) std::sregex_iterator numberIt(text.begin(), text.end(), regNumber); // (3) const std::sregex_iterator numberEnd; for (; numberIt != numberEnd; ++numberIt) { std::cout << numberIt->str() << std::endl; // (4) } std::cout << std::endl; const std::regex regComma(","); std::sregex_token_iterator commaIt(text.begin(), text.end(), regComma, -1); // (5) const std::sregex_token_iterator commaEnd; for (; commaIt != commaEnd; ++commaIt) { std::cout << commaIt->str() << std::endl; } std::cout << std::endl; std::vector<std::string> resVec = splitAt(text, regComma); // (7) for (auto s : resVec) std::cout << s << " "; std::cout << "\n\n"; resVec = splitAt("abc5.4def-10.5hij2e-5klm", regNumber); // (8) for (auto s : resVec) std::cout << s << " "; std::cout << "\n\n"; std::regex regSpace(R"(\s+)"); resVec = splitAt("abc 123 456\t789 def hij\nklm", regSpace); // (9) for (auto s : resVec) std::cout << s << " "; std::cout << "\n\n"; }
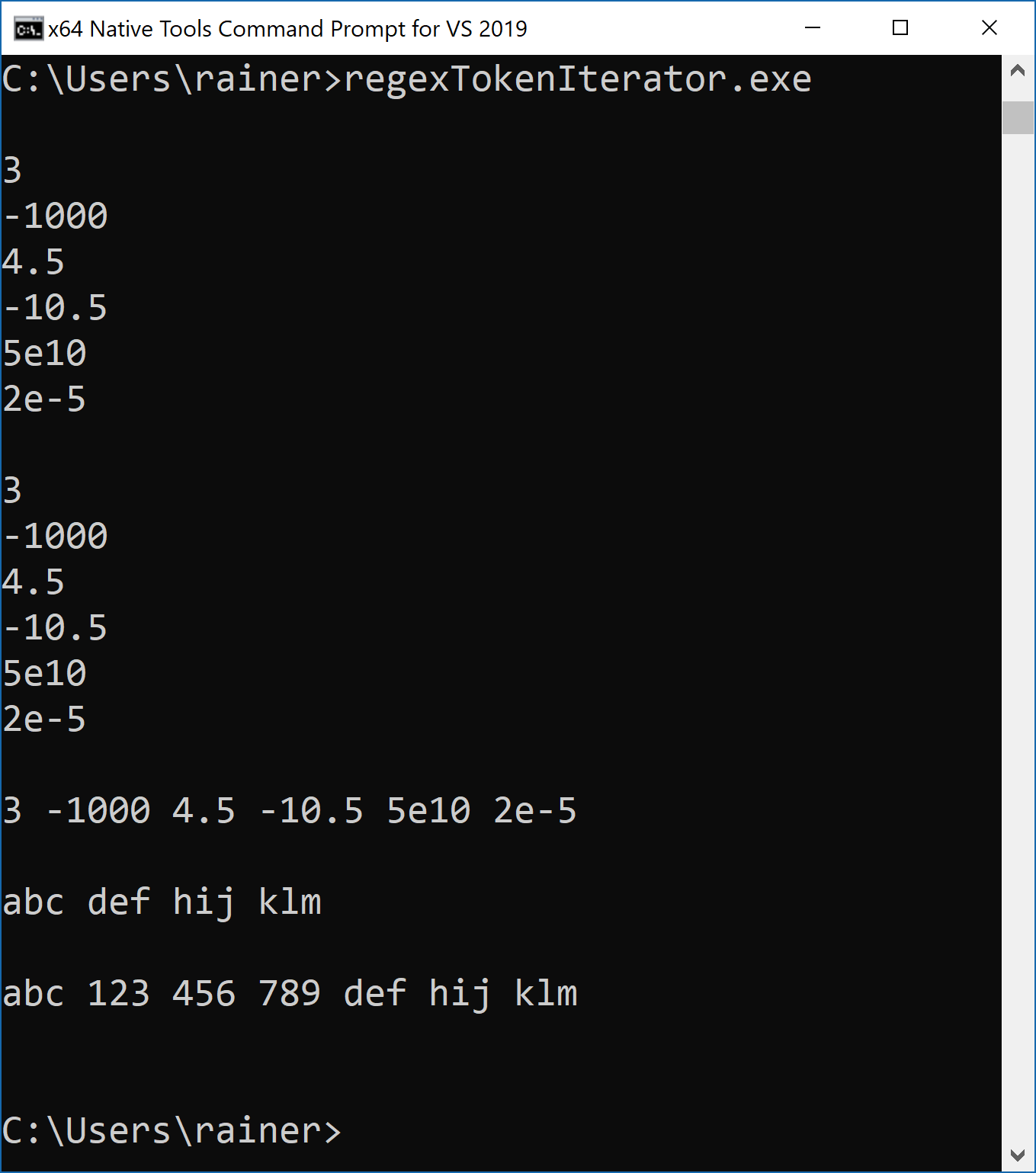
Line 1 contains a string of numbers separated by commas. To get all numbers, I define in line 2 a regular expression which matches each number. All numbers include natural numbers, floating-point numbers, and numbers written in scientific notation. Line 3 defines the iterator of type std::sregex_iterator, which gives me all tokens and displays them in line 4. The std::regex_token_iterator in line 5 is more powerful. It searches for commas and gives me the text between them because I used the negative index -1.
This pattern is so convenient that I put it in the function splitAt (line 6). splitAt takes a text and a regular expression, applies the regular expression to the text, and pushes the text between the regular expression onto the std::vector<std::string> res. Now, it’s pretty easy to split a text on commas (line 7), on numbers (line 8), and spaces (line 9).
As Martin Stockmayer suggested, you can write the function splitAt more concisely, because a std::vector can directly deal with a begin and an end iterator.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
std::vector<std::string> splitAt(const std::string &text, const std::regex ®) { return std::vector<std::string>(std::sregex_token_iterator(text.begin(), text.end(), reg, -1), std::sregex_token_iterator()); }
The output of the program shows the expected behavior:
Okay, this was my last rule for the regular expression library, and I, therefore, finished the rules for the standard library of the C++ core guidelines. But hold, there is one rule to the C standard library.
SL.C.1: Don’t use setjmp/longjmp
The reason for this rule is relatively concise: a longjmp ignores destructors, thus invalidating all resource-management strategies relying on RAII. I hope you know RAII. If not, here is the gist.
RAII stands for Resource Acquisition Is Initialization. Probably, the most crucial idiom in C++ says that a resource should be acquired in the constructor and released in the destructor of the object. The key idea is that the destructor will automatically be called if the object goes out of scope.
The following example shows the deterministic behavior of RAII in C++.
// raii.cpp #include <iostream> #include <new> #include <string> class ResourceGuard{ private: const std::string resource; public: ResourceGuard(const std::string& res):resource(res){ std::cout << "Acquire the " << resource << "." << std::endl; } ~ResourceGuard(){ std::cout << "Release the "<< resource << "." << std::endl; } }; int main(){ std::cout << std::endl; ResourceGuard resGuard1{"memoryBlock1"}; // (1) std::cout << "\nBefore local scope" << std::endl; { ResourceGuard resGuard2{"memoryBlock2"}; // (3) } // (4) std::cout << "After local scope" << std::endl; std::cout << std::endl; std::cout << "\nBefore try-catch block" << std::endl; try{ ResourceGuard resGuard3{"memoryBlock3"}; throw std::bad_alloc(); // (5) } catch (std::bad_alloc& e){ // (6) std::cout << e.what(); } std::cout << "\nAfter try-catch block" << std::endl; std::cout << std::endl; } // (2)
ResourceGuard is a guard that manages its resource. In this case, the string stands for the resource. ResourceGuard creates in its constructor the resource and releases the resource in its destructor. It does its job very decent.
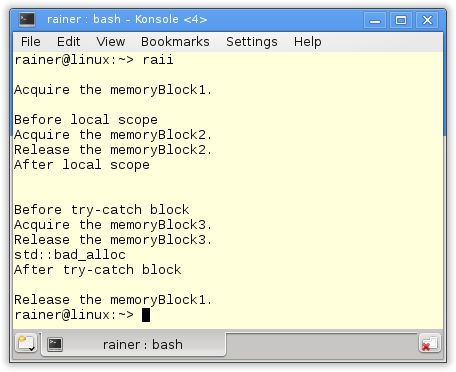
The destructor of resGuard1 (line 1) is called at the end of the main function (line 2). The lifetime of resGuard2 (line 3) already ends in line 4. Therefore, the destructor is automatically executed. Even throwing an exception does not affect the reliability of resGuard3 (line 5). The destructor is called at the end of the try block (line 6).
The screenshot shows the lifetimes of the objects.
I want to emphasize the critical idea of RAII: A resource’s lifetime is bound to a local variable’s lifetime, and C++ automatically manages the lifetime of locals.
Okay, but how can setjmp/longjmp break this automatism? Here is what the macro setjmp and std::longjmp does:
int setjmp(std::jmp_buf env):
- saves the execution context in env for std::longjmp
- returns in its first direct invocation, 0
- returns in further invocations by std::longjmp the value set by std::longjmp
- it is the target for the std::longjmp call
- corresponds to catch in exception handling
void std::longjmp(std::jmp_buf env, int status):
- restores the execution context stored in env
- set the status for the setjmp call
- corresponds to throw in exception handling
Okay, this was quite technical. Here is a simple example.
// setJumpLongJump.cpp #include <cstdlib> #include <iostream> #include <csetjmp> #include <string> class ResourceGuard{ private: const std::string resource; public: ResourceGuard(const std::string& res):resource(res){ std::cout << "Acquire the " << resource << "." << std::endl; } ~ResourceGuard(){ std::cout << "Release the "<< resource << "." << std::endl; } }; int main(){ std::cout << std::endl; std::jmp_buf env; volatile int val; val = setjmp(env); // (1) if (val){ std::cout << "val: " << val << std::endl; std::exit(EXIT_FAILURE); } { ResourceGuard resGuard3{"memoryBlock3"}; // (2) std::longjmp(env, EXIT_FAILURE); // (3) } // (4) }
The call in line (1) saves the execution environment and returns 0. This execution environment is restored in line (3). The critical observation is that the destructor of resGuard3 (line 2) is not invoked in line 4. In the concrete case, you would get a memory leak, or a mutex wouldn’t be unlocked.
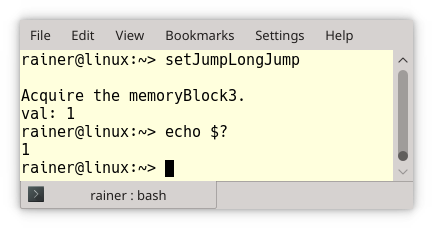
EXIT_FAILURE is the return value of the second setjmp call (line 1) and the executable’s return value.
What’s next?
DONE, but not completely! I have written over 100 posts on the main sections of the C++ core guidelines and learned a lot. Besides the main section, the guidelines also have supporting sections that sound very interesting. I will write about it in my next post.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org





Leave a Reply
Want to join the discussion?Feel free to contribute!