
Parallel Algorithms of the Standard Template Library
The idea is quite simple. The Standard Template has more than 100 algorithms for searching, counting, and manipulating ranges and their elements. With C++17, 69 are overloaded, and a few new ones are added. The overloaded and new algorithms can be invoked with a so-called execution policy. Using the execution policy, you can specify whether the algorithm should run sequentially, parallel, or parallel and vectorized.
A first example
Vectorization stands for the SIMD (Single Instruction, Multiple Data) extensions of the instruction set of a modern processor. SIMD enables your processor to execute one operation in parallel on several data.
The policy tag chooses which overloaded variant of an algorithm is used. How does that work?
1 2 3 4 5 6 7 8 9 10 11 12 13 |
vector<int> v = ... // standard sequential sort std::sort(v.begin(), v.end()); // sequential execution std::sort(std::parallel::seq, v.begin(), v.end()); // permitting parallel execution std::sort(std::parallel::par, v.begin(), v.end()); // permitting parallel and vectorized execution std::sort(std::parallel::par_unseq, v.begin(), v.end()); |
The example shows you can even use the classic variant of std::sort (line 4). On contrary, you explicitly specify in C++17 whether the sequential (line 7), parallel (line 10) or parallel and vectorized (line 13) version is used.
You have to keep two points in mind.
Two special points
On the one hand, an algorithm will not always be performed parallel and vectorized if you use the execution policy std::parallel::par_unseq. On the other hand, you, as the user, are responsible for correctly using the algorithm.
Parallel and vectorized execution
Whether an algorithm runs in a parallel and vectorized way depends on many points. It depends if the CPU and the operating system support SIMD instructions. Additionally, it’s a question of the compiler and the optimization level you used to translate your code.
1 2 3 4 5 6 7 8 9 10 |
const int SIZE= 8; int vec[]={1,2,3,4,5,6,7,8}; int res[SIZE]={0,}; int main(){ for (int i= 0; i < SIZE; ++i) { res[i]= vec[i]+5; } } |
Line 8 is the key line in the small program. Thanks to the compiler explorer https://godbolt.org/ , it is quite easy to generate the assembler instructions for clang 3.6 with and without maximum optimization (-03).
Without Optimisation
Although my time fiddling with assembler instruction is long gone, it’s evident that all is done sequentially.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
With maximum optimization
I get instructions that run in parallel on several data by using maximum optimization.

The move operation (movdqa) and the add operation (paddd) use the special registers xmm0 and xmm1. Both registers are so-called SSE registers and have 128 Bits. SSE stands für Streaming SIMD Extensions.
Hazards of data races and deadlocks
The algorithm does not automatically protect from data races and deadlocks. Example?
int numComp= 0; std::vector<int> vec={1,3,8,9,10}; std::sort(std::parallel::vec, vec.begin(), vec.end(), [&numComp](int fir, int sec){ numComp++; return fir < sec; });
The small code snippet has a data race. numComp counts the number of operations. That means, in particular, that numComp is modified in the lambda function; therefore, the code snippet has a data race. To be well-defined, numComp has to be an atomic variable.
The static versus dynamic execution policy
Sorry to say, but the execution policy made it not in the C++17 standard. We have to wait for C++20.
Creating a thread is expensive; therefore, it makes no sense to sort a small container in a parallel (std::parallel::par) or parallel and vectorised (std::parallel:par_unseq) fashion. The administrative overhead of dealing with threads will outweigh the benefit of parallelization. It even gets worse if you use a divide and conquer algorithm such as quicksort.
1 2 3 4 5 6 7 8 9 10 11 |
template <class ForwardIt> void quicksort(ForwardIt first, ForwardIt last){ if(first == last) return; auto pivot = *std::next(first, std::distance(first,last)/2); ForwardIt middle1 = std::partition(std::parallel::par, first, last, [pivot](const auto& em){ return em < pivot; }); ForwardIt middle2 = std::partition(std::parallel::par, middle1, last, [pivot](const auto& em){ return !(pivot < em); }); quicksort(first, middle1); quicksort(middle2, last); } |
The issue is that the number of threads is too big for your system. To solve this issue, C++17 supports a dynamic execution policy.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
std::size_t threshold= ...; // some value template <class ForwardIt> void quicksort(ForwardIt first, ForwardIt last){ if(first == last) return; std::size_t distance= std::distance(first,last); auto pivot = *std::next(first, distance/2); std::parallel::execution_policy exec_pol= std::parallel::par; if ( distance < threshold ) exec_pol= std::parallel_execution::seq; ForwardIt middle1 = std::partition(exec_pol, first, last, [pivot](const auto& em){ return em < pivot; }); ForwardIt middle2 = std::partition(exec_pol, middle1, last, [pivot](const auto& em){ return !(pivot < em); }); quicksort(first, middle1); quicksort(middle2, last); } |
I use in lines 9 and 10 the dynamic execution policy. By default, quicksort will run in parallel (line 9). If the length of the range is smaller than a given threshold (line 1), quicksort will run sequentially (line 10).
All algorithms
69 of the algorithms of the STL support a parallel or a parallel and vectorized execution. Here they are.
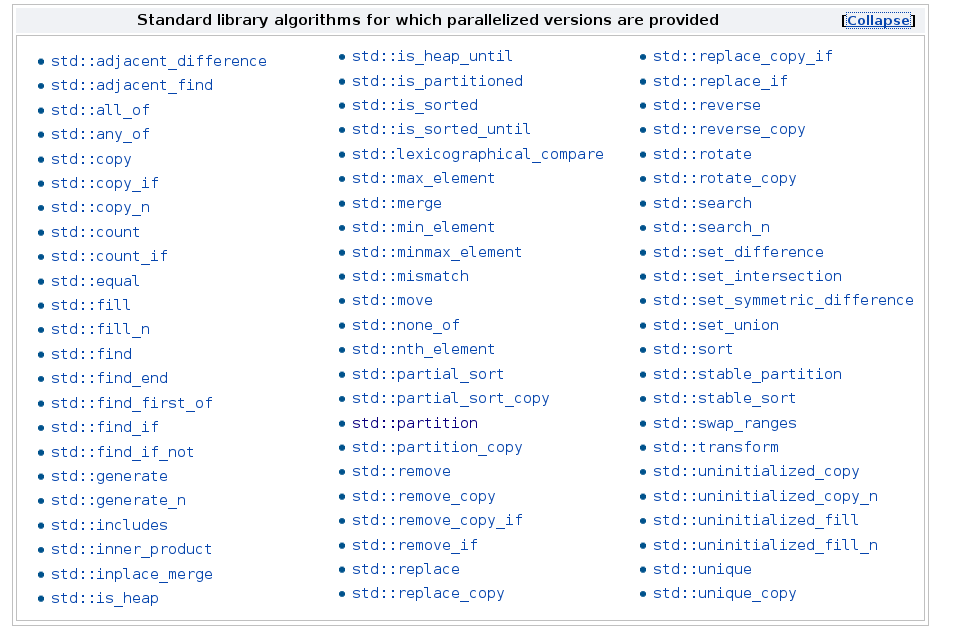
In addition, we get eight new algorithms.
New algorithms
The new variation of std::for_each and the new algorithms std::for_each_n, std::exclusive_scan, std::inclusive_scan, std::transfom_exclusive_scan , std::transform_inclusive_scan, std::reduce and std::transform_reduce are in the std namespace.
std::for_each std::for_each_n std::exclusive_scan std::inclusive_scan std::transform_exclusive_scan std::transform_inclusive_scan std::reduce std::transform_reduce
Let’s have closer look at std::transform_reduce.
transform becomes map
The Haskell known function map is called std::transform in C++. If that is not a broad hint. When substituting the name std::transform_reduce transform with map, I will get std::map_reduce. MapReduce is the well-known parallel framework that maps each value to a new value in the first phase and reduces all values to the result in the second phase.
The algorithm is directly applicable in C++17. Of course, my algorithm will not run on a big, distributed system, but the strategy is the same; therefore, I map in the map phase each word to its length and reduce in the reduce phase the lengths of all words to their sum. The result is the sum of the lengths of all words.
std::vector<std::string> str{"Only","for","testing","purpose"};
std::size_t result= std::transform_reduce(std::parallel::par,
str.begin(), str.end(),
[](std::string s){ return s.length(); },
0, [](std::size_t a, std::size_t b){ return a + b; });
std::cout << result << std::endl; // 21
The 0 is the initial element for the reduction.
What’s next?
With the next post, I will go three years further. In C++20, we get atomic smart pointers. Following their C++11 pendants, they are called std::atomic_shared_ptr and std::atomic_weak_ptr.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Phillip Diekmann, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org

Leave a Reply
Want to join the discussion?Feel free to contribute!