Ongoing Optimization: A Data Race with CppMem
But we can improve and further improve the acquire-release semantics of the last post. Why should x be atomic? There is no reason. That was my first but incorrect assumption. See why?
A typical misunderstanding in applying the acquire-release semantic is to assume that the acquire operation is waiting for the release operation. So based on this assumption, you may think that x has not be an atomic variable. So we can further optimize the program.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
// ongoingOptimizationAcquireReleaseBroken.cpp #include <atomic> #include <iostream> #include <thread> int x= 0; std::atomic<int> y{0}; void writing(){ x= 2000; y.store(11,std::memory_order_release); } void reading(){ std::cout << y.load(std::memory_order_acquire) << " "; std::cout << x << std::endl; } int main(){ std::thread thread1(writing); std::thread thread2(reading); thread1.join(); thread2.join(); }; |
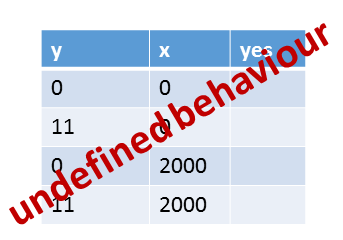
The program has a data race on x and has, therefore, undefined behavior. If y.store(11,std::memory_order_release) (line 12) is executed before y.load(std::memory_order_acquire) (line 16), the acquire-release semantic guarantees that x= 2000 (line 11) is executed before the reading of x in line 17. But if not. In this case, the reading of x will be executed simultaneously as the writing of x. So we have concurrent access to a shared variable, one of them is a write. That’s, per definition, a data race.
The table puts it in a nutshell.
I made this mistake in my presentation “Multithreading done right?” in Berlin. In Moscow, I did it right. I never claimed that the C++ memory model is a piece of cake.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
Now it’s time for CppMem. Let’s see what CppMem finds out.
CppMem
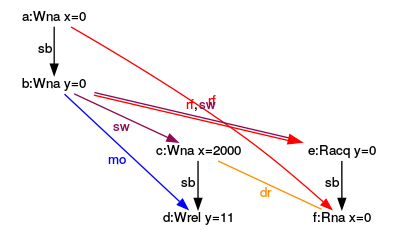
int main(){ int x= 0; atomic_int y= 0; {{{ { x= 2000; y.store(11,memory_order_release); } ||| { y.load(memory_order_acquire); x; } }}} }
The data race occurs if one thread writes x= 2000 and the other reads x. The graph shows a dr symbol (data race) on the arrow.
What’s next?
The ultimate step in the process of ongoing optimization is still missing. In the next post, I will use the relaxed semantic.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org






Leave a Reply
Want to join the discussion?Feel free to contribute!