Multithreading with C++17 and C++20
Forecasts about the future are difficult. In particular, when they are about C++20. Nevertheless, I will take a look into the crystal ball and will write in the next posts about, what we will get with C++17 and what we can hope for with C++20.
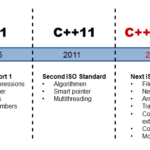
Since C++11 C++ faces the requirements of the multicore architectures. The 2011 published standard defines, how a program should behave in the presence of many threads. The multithreading capabilities of C++11 consist of two parts. On the hand, there is the well-defined memory model; on the other hand, there is the standardised threading API.
The well-defined memory model deals with the following questions.
- What are atomic operations?
- Which sequence of operations is guaranteed?
- When are the memory effects of operations visible?
The standardised threading interface in C++11 consists of the following components.
- Threads
- Tasks
- Thread-local data
- Condition variables
If that is not too boring for you, read the posts about the memory model and the standardised threading API.
Wearing my multithreading glasses, C++14 has not much to offer. C++14 added Reader-Writer Locks.
The questions, which arises, is: What has the C++ future to offer?
C++17
With C++17, most of the algorithms of the Standard Template Library will be available in a parallel version. Therefore, you can invoke an algorithm with a so-called execution policy. This execution policy specifies if the algorithm runs sequential (std::seq), parallel (std::par), or parallel and vectorised (std::par_unseq).
std::vector<int> vec ={3, 2, 1, 4, 5, 6, 10, 8, 9, 4};
std::sort(vec.begin(), vec.end()); // sequential as ever
std::sort(std::execution::seq, vec.begin(), vec.end()); // sequential
std::sort(std::execution::par, vec.begin(), vec.end()); // parallel
std::sort(std::execution::par_unseq, vec.begin(), vec.end()); // parallel and vectorized
std::vector<int> vec ={3, 2, 1, 4, 5, 6, 10, 8, 9, 4};std::sort(vec.begin(), vec.end()); // sequential as everstd::sort(std::execution::seq, vec.begin(), vec.end()); // sequentialstd::sort(std::execution::par, vec.begin(), vec.end()); // parallelstd::sort(std::execution::par_unseq, vec.begin(), vec.end()); // parallel and vectorized
Therefore, the first and second variations of the sort algorithm run sequential, the third parallel, and the fourth parallel and vectorised.
C++20 offers totally new multithreading concepts. The key idea is that multithreading becomes a lot simpler and less error-prone.
C++20
Atomic smart pointer
The atomic smart pointer std::shared_ptr and std::weak_ptr have a conceptional issue in multithreading programs. They share a mutable state. Therefore, they a prone to data races and therefore undefined behaviour. std::shared_ptr and std::weak_ ptr guarantee that the in- or decrementing of the reference counter is an atomic operation and the resource will be deleted exactly once, but both does not guarantee that the access to its resource is atomic. The new atomic smart pointers solve this issue.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
std::atomic_shared_ptrstd::atomic_weak_ptr
With tasks called promises and futures, we got a new multithreading concept in C++11. Although tasks have a lot to offer, they have a big drawback. Futures can not be composed in C++11.
std::future extensions
That will not hold for futures in C++20. Therefore, a future becomes ready, when
- its predecessor becomes ready:
then:
future<int> f1= async([]() {return 123;});future<string> f2 = f1.then([](future<int> f) { return f.get().to_string(); });
- one of its predecessors become ready:
when_any:
future<int> futures[] = {async([]() { return intResult(125); }), async([]() { return intResult(456); })};future<vector<future<int>>> any_f = when_any(begin(futures),end(futures));
- all of its predecessors become ready:
when_all:
future<int> futures[] = {async([]() { return intResult(125); }), async([]() { return intResult(456); })};future<vector<future<int>>> all_f = when_all(begin(futures), end(futures));
C++14 has no semaphores. Semaphores enable it that threads can control access to a common resource. No problem, with C++20 we get latches and barriers.
Latches and barriers
You can use latches and barriers for waiting at a synchronisation point until the counter becomes zero. The difference is, std::latch can only be used once; std::barrier and std::flex_barrier more the once. In contrary to a std::barrier, a std::flex_barrier can adjust its counter after each iteration.
| 1 2 3 4 5 6 7 8 9101112 | void doWork(threadpool* pool){ latch completion_latch(NUMBER_TASKS); for (int i = 0; i < NUMBER_TASKS; ++i){ pool->add_task([&]{ // perform the work … completion_latch.count_down(); }); } // block until all tasks are done completion_latch.wait();} |
The thread running the function doWork is waiting in line 11 until the completion_latch becomes 0. The completion_latch is set to NUMBER_TASKS in line 2 and decremented in line 7.
Coroutines are generalised functions. In contrary to functions, you can suspend and resume the execution of the coroutine while keeping its state.
Coroutines
Coroutines are often the means of choice to implement cooperative multitasking in operating systems, event loop, infinite lists, or pipelines.
| 1 2 3 4 5 6 7 8 910 | generator<int> getInts(int first, int last){ for (auto i= first; i <= last; ++i){ co_yield i; }}int main(){ for (auto i: getInts(5, 10)){ std::cout << i << ” “; // 5 6 7 8 9 10} |
The function getInts (line 1 – 5) gives back a generator that returns on request a value. The expression co_yield serves two purposes. At first, it returns a new value and a second, it waits until a new value is requested. The range-based for-loop successively requests the values from 5 to 10.
With transaction memory, the well-established idea of transactions will be applied in software.
Transactional memory
The transactional memory idea is based on transactions from the database theory. A transaction is an action that provides the properties Atomicity, Consistency, Isolation and Durability (ACID). Except for durability, all properties will hold for transactional memory in C++. C++ will have transactional memory in two flavours. One is called synchronised blocks and the other atomic blocks. Both have in common that they will be executed in total order and behave as they were protected by a global lock. In contrary to synchronised blocks, atomic blocks can not execute transaction-unsafe code.
Therefore, you can invoke std::cout in a synchronised block but not in an atomic block.
| 1 2 3 4 5 6 7 8 91011121314 | int func() { static int i = 0; synchronized{ std::cout << “Not interleaved n”; ++i; return i; } } int main(){ std::vector<std::thread> v(10); for(auto& t: v) t = std::thread([]{ for(int n = 0; n < 10; ++n) func(); });} |
The synchronized keyword in line 3 guarantees that the execution of the synchronised block (line 3 – 7) will not overlap. That means in particular that there is a single, total order between all synchronised blocks. To say it the other way around. The end of each synchronised block synchronizes with the start of the next synchronised block.
Although I called this post Multithreading in C++17 and C++20, we get with task blocks beside the parallel STL more parallel features in C++.
Task blocks
Task Blocks implement the fork-join paradigm. The graphic shows the key idea.
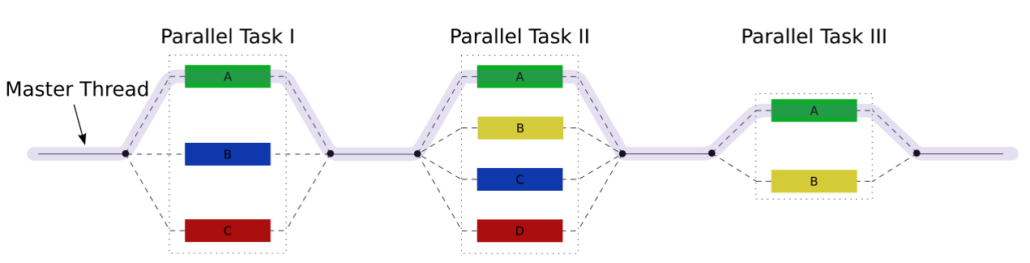
By using run in a task block you can fork new tasks that will be joined at the end of the task block.
| 1 2 3 4 5 6 7 8 91011 | template <typename Func> int traverse(node& n, Func && f){ int left = 0, right = 0; define_task_block( [&](task_block& tb){ if (n.left) tb.run([&]{ left = traverse(*n.left, f); }); if (n.right) tb.run([&]{ right = traverse(*n.right, f); }); } ); return f(n) + left + right; } |
traverse is a function template that invokes the function Func on each node of its tree. The expression define_task_block defines the task block. In this region, you have a task block tb to your disposal to start new tasks. Exactly that is happening in the left and right branch of the tree (line 6 and 7). Line 9 is the end of the task block and therefore the synchronisation point.
What’s next?
After I have given the overview of the new multithreading features in C++17 and C++20, I will provide the details in the next posts. I will start with the parallel STL. I’m quite sure that my post has left more question open than answered.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org

Leave a Reply
Want to join the discussion?Feel free to contribute!