
C++ Core Guidelines: Non-Rules and Myths
Of course, you already know many non-rules and myths about C++. Non-rules and myths which we have to argue against when we use modern C++. The supporting section of the C++ core guidelines addresses the most resistant ones but also provides alternatives.

Here are the rules for today.
- NR.1: Don’t: All declarations should be at the top of a function
- NR.2: Don’t: Have only a single
return-statement in a function - NR.3: Don’t: Don’t use exceptions
- NR.4: Don’t: Place each class declaration in its own source file
Many programmers apply the first rules.
NR.1: Don’t: All declarations should be at the top of a function
This rule is a relict of old programming languages that don’t allow the initialization of variables and constants after a statement. The result of a significant distance of the variable declaration and their usage is often that you forget to initialize the variable. Exactly this happens in the example of the C++ core guidelines:
int use(int x) { int i; char c; double d; // ... some stuff ... if (x < i) { // ... i = f(x, d); } if (i < x) { // ... i = g(x, c); } return ; }
I assume you already found the issue in this code snippet. The variable i (the same holds for c and d) is not initialized because it is a built-in variable used in a local scope. Therefore, the program has undefined behavior. If it were a user-defined type such as std::string, all would be fine. So, what should you do:
- Place the declaration of i directly before its first usage.
- Always initialize a variable such as int i{}, or better, use auto. The compiler can not guess from a declaration such as auto i; the type of i and will, therefore, reject the program. To put it the other way around auto forces you to initialize your variables.
I also know the next rule from discussions.
NR.2: Don’t: Have only a single return-statement in a function
When you follow this rule, you implicitly apply the first non-rule.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
template<class T> std::string sign(T x) // bad { std::string res; if (x < 0) res = "negative"; else if (x > 0) res = "positive"; else res = "zero"; return res; }
Using more return statements makes the code easier to read and also faster.
template<class T> std::string sign(T x) { if (x < 0) return "negative"; else if (x > 0) return "positive"; return "zero"; }
Okay. What happens if I use automatic return type deduction return different types?
// differentReturnTypes.cpp template <typename T> auto getValue(T x){ if (x < 0) // int return -1; else if (x > 0) return 1.0; // double else return 0.0f; // float } int main(){ getValue(5.5); }
As expected, just an error:
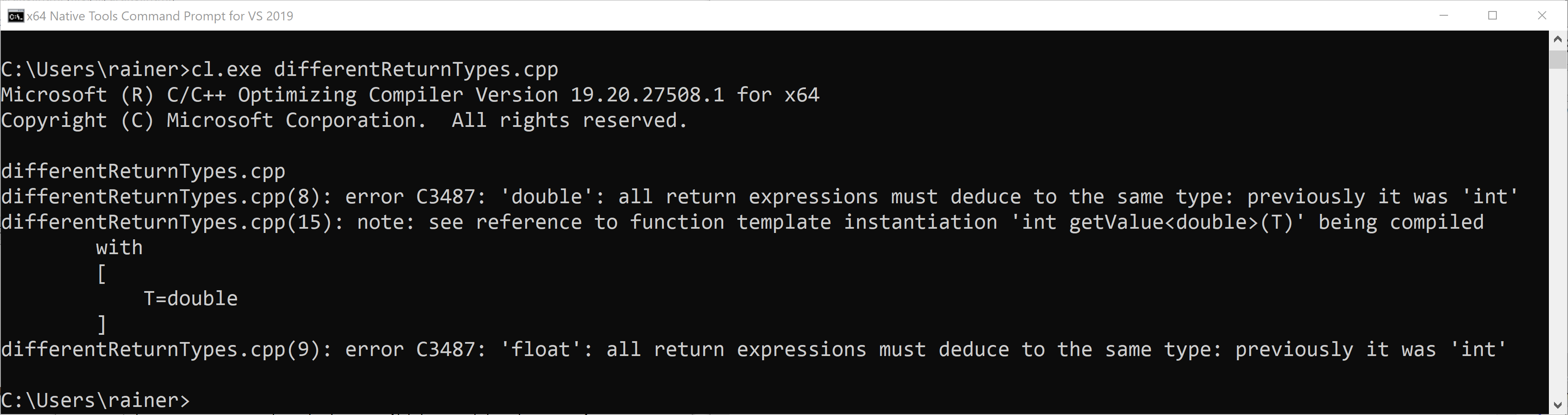
Probably, the next non-rule is the most controversial one.
NR.3: Don’t: Don’t use exceptions
First, the guideline states the main reasons against exceptions:
- exceptions are inefficient
- exceptions lead to leaks and errors
- exception performance is not predictable
The guidelines have profound answers to these statements.
1. Often, the efficiency of exception handling is compared to a program that just terminated or displays the error code. Often the exception-handling implementation is poor. Of course, a comparison makes in such cases no sense. I want to explicitly mention the paper Technical Report on C++ Performance (TR18015.pdf), which presents two typical ways to implement exceptions:
- The code approach, where code is associated with each try-block
- The “table” approach, which uses compiler-generated static tables
Roughly said, the “code” approach has the downside that even when no exceptions are thrown, the bookkeeping of the exception handling stack must be performed, and, therefore, code unrelated to error handling slows down. This downside does not hold for the “table” approach because it introduces no stack or runtime costs when no exception is thrown. In contrast, the “table” approach seems more complicated, and the static table can get quite big.
2. I have nothing to add to point 2. Exceptions can not be blamed for a missing resource management strategy.
3. If you have hard-realtime guarantees to fulfill so that a too-late answer is a wrong answer, an exception implementation based on the “table” approach will not – as we saw – affect the program’s run-time in the excellent case. Honestly, even if you have a hard-realtime system, this hard-realtime restriction typically only holds for a small part of your system.
Instead of arguing against the non-rules, here are the reasons for using exceptions:
Exceptions
- differentiate between an erroneous return and an ordinary return.
- cannot be forgotten or ignored.
- can be used systematically.
Let me add an anecdote I once faced in legacy code. The system used error codes to signal the success or failure of a function. Okay, they checked the error codes. This was fine. But due to the error codes, the functions didn’t use return values. The consequence was that the functions operated on global variables and had no parameters because they used the global variables anyway. The end of the story was that the system was not maintainable or testable, and my job was it to refactor it.
The typical wrong usage of exception handling I see is the following one. You catch every exception in every function. In the end, you get unmaintainable code with a spaghetti-like structure. Exceptions are not a tool to make a fast fix but should be part of the overall system architecture. Imagine you design an input sub-system. You must also document and test the exceptions that can occur. Exceptions are an essential part of the non-functional channel and, therefore, part of the contract you provide to your sub-system user. It would help to have a clear boundary between the application and the sub-system. The result may be that the sub-system translates the obscure exceptions into simpler ones so the application can react. Translating an exception means that you catch obscure exceptions in the sub-system and re-throw an easy-do-digest exception:
try{
// code, that may throw an obscure exception
}
catch (ObscureException18& ob){
throw InputSubsystemError("File has wrong permissions!");
}
The result of such a system architecture including the non-functional channel (exceptions) is that you can test the sub-system in isolation, you can test the integration of the sub-system into the application, and you can test the system (application).
The last myth for today is relatively easy to spot.
NR.4: Don’t: Place each class declaration in its own source file
The correct way to structure your code is not to use files but to use namespaces. Using a file for each class declaration results in many files, making your program more complicated to manage and slower to compile.
What’s next?
You can be sure. The C++ core guidelines and I’m not done with the non-rules and myths of C++. I will continue in my next post. Afterward, when you encounter the non-rules and myths, you should know how to demystify them.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org



Leave a Reply
Want to join the discussion?Feel free to contribute!