
Atomics
In addition to booleans, there is atomics for pointers, integrals, and user-defined types. The rules for user-defined types are special.
Both. The atomic wrapper on a pointer T* std::atomic<T*> or on an integral type integ std::atomic<integ> enables the CAS (compare-and-swap) operations.
std::atomic<T*>
The atomic pointer std::atomic<T*> behaves like a plain pointer T*. So std::atomic<T*> supports pointer arithmetic and pre-and post-increment or pre-and post-decrement operations. Have a look at the short example.
int intArray[5]; std::atomic<int*> p(intArray); p++; assert(p.load() == &intArray[1]); p+=1; assert(p.load() == &intArray[2]); --p; assert(p.load() == &intArray[1]);
std::atomic<integral type>
In C++11, there are atomic types to the known integral data types. As ever, you can read the whole stuff about atomic integral data types – including their operations – on the page en.cppreference.com. A std::atomic<integral type> allows all that a std::atomic_flag or a std::atomic<bool> is capable of, but even more.
The composite assignment operators +=, -=, &=, |= and ^= and there pedants std::atomic<>::fetch_add(), std::atomic<>::fetch_sub(), std::atomic<>::fetch_and(), std::atomic<>::fetch_or() and std::atomic<>::fetch_xor() are the most interesting ones. There is a little difference in the atomic read and write operations. The composite assignment operators return the new value, and the fetch variations the old value. A deeper look gives more insight. There is no multiplication, division, and shift operation in an atomic way. But that is not that big a restriction because these operations are relatively seldom needed and can easily be implemented. How? Look at the example.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
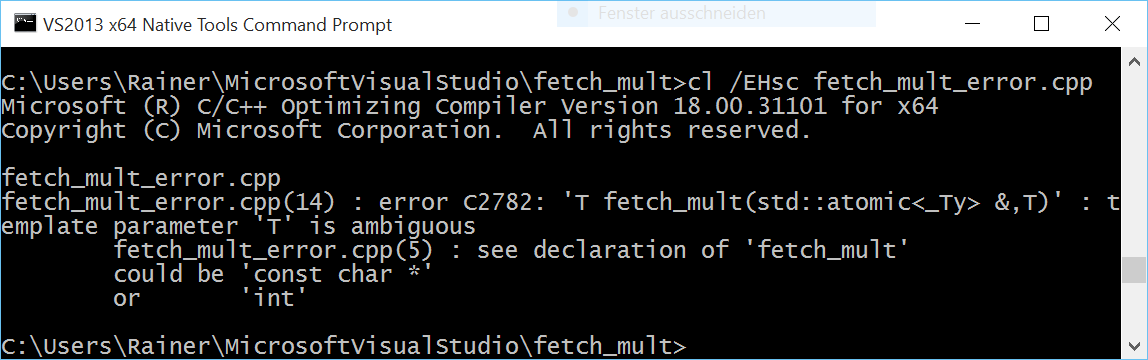
// fetch_mult.cpp #include <atomic> #include <iostream> template <typename T> T fetch_mult(std::atomic<T>& shared, T mult){ T oldValue= shared.load(); while (!shared.compare_exchange_strong(oldValue, oldValue * mult)); return oldValue; } int main(){ std::atomic<int> myInt{5}; std::cout << myInt << std::endl; fetch_mult(myInt,5); std::cout << myInt << std::endl; } |
I should mention one point. The addition in line 9 will only happen if the relation oldValue == shared holds. So to be sure that the multiplication will always take place, I put the multiplication in a while loop. The result of the program is not so thrilling.

The implementation of the function template fetch_mult is generic, too generic. So you can use it with an arbitrary type. In case I use instead of the number 5 the C-String 5, the Microsoft compiler complains that the call is ambiguous.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
“5” can be interpreted as a const char* or an int. That was not my intention. The template argument should be an integral type. The correct use case for concepts lite. With concepts lite, you can express constraints to the template parameter. Sad to say, but they will not be part of C++17. We should hope for the C++20 standard.
1 2 3 4 5 6 7 |
template <typename T> requires std::is_integral<T>::value T fetch_mult(std::atomic<T>& shared, T mult){ T oldValue= shared.load(); while (!shared.compare_exchange_strong(oldValue, oldValue * mult)); return oldValue; } |
The predicate std::is_integral<T>::value will be evaluated by the compiler. If T is not an integral type, the compiler will complain. std::is_integral is a function of the new type-traits library, part of C++11. The required condition in line 2 defines the constraints on the template parameter. The compiler checks the contract at compile time.
You can define your atomic types.
std::atomic<user defined type>
There are a lot of severe restrictions on a user-defined type to get an atomic type std::atomic<MyType>. These restrictions are on the type but on the available operations that std::atomic<MyType> can perform.
For MyType, there are the following restrictions:
- The copy assignment operator for MyType must be trivial for all base classes of MyType and all non-static members of MyType. Only an automatic by the compiler-generated copy assignment operator is trivial. To say it the other way around. User-defined copy assignment operators are not trivial.
- MyType must not have virtual methods or base classes.
- MyType must be bitwise comparable so that the C functions memcpy or memcmp can be applied.
You can check the constraints on MyType with the functions std::is_trivially_copy_constructible, std::is_polymorphic, and std::is_trivial at compile time. All the functions are part of the type-traits library.
Only a reduced set of operations is supported for the user-defined type, std::atomic<MyType>.
Atomic operations
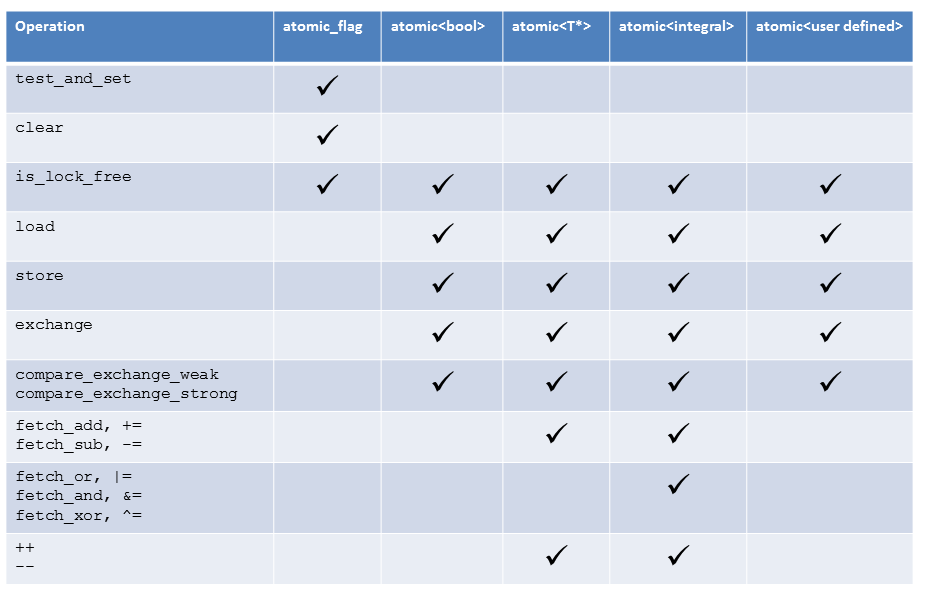
To get the great picture, I displayed the atomic operations dependent on the atomic type in the following table.
Free atomic functions and smart pointers
The functionality of the class templates std::atomic and the Flag std::atomic_flag can be used as a free function. Because the free functions use atomic pointers instead of references, they are compatible with C. The atomic free functions support the same types as the class template std::atomic but in addition to that the smart pointer std::shared_ptr. That is special because std::shared_ptr is not an atomic data type. The C++ committee recognized the necessity that instances of smart pointers that maintain the reference counters and objects under their hood must be modifiable in an atomic way.
std::shared_ptr<MyData> p;
std::shared_ptr<MyData> p2= std::atomic_load(&p);
std::shared_ptr<MyData> p3(new MyData);
std::atomic_store(&p, p3);
To be clear. The atomic characteristic will only hold for the reference counter but not the object. That was the reason we get a std::atomic_shared_ptr in the future (I’m not sure if the future is called C++17 or C++20. I was often wrong in the past.), which is based on a std::shared_ptr and guarantees the atomicity of the underlying object. That will also hold for std::weak_ptr. std::weak_ptr, which is a temporary resource owner, helps break the cyclic dependencies of std::shared_ptr. The name of the new atomic std::weak_ptr will be std::atomic_weak_ptr. To complete the picture, the atomic version of std::unique_ptr is called std::atomic_unique_ptr.
What’s next?
Now the foundations of the atomic data types are laid. In the next post, I will write about the synchronization and ordering constraints on atomics.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org







Leave a Reply
Want to join the discussion?Feel free to contribute!