Asynchronous Function Calls
std:.async feels like an asynchronous function call. Under the hood std::async is a task. One, which is extremely easy to use.
std::async
std::async gets a callable as a work package. In this example, it’s a function, a function object, or a lambda function.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
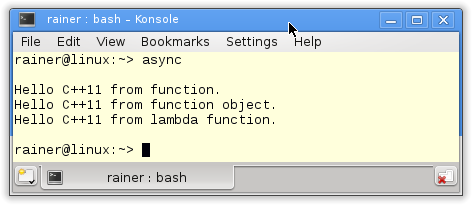
// async.cpp #include <future> #include <iostream> #include <string> std::string helloFunction(const std::string& s){ return "Hello C++11 from " + s + "."; } class HelloFunctionObject{ public: std::string operator()(const std::string& s) const { return "Hello C++11 from " + s + "."; } }; int main(){ std::cout << std::endl; // future with function auto futureFunction= std::async(helloFunction,"function"); // future with function object HelloFunctionObject helloFunctionObject; auto futureFunctionObject= std::async(helloFunctionObject,"function object"); // future with lambda function auto futureLambda= std::async([](const std::string& s ){return "Hello C++11 from " + s + ".";},"lambda function"); std::cout << futureFunction.get() << "\n" << futureFunctionObject.get() << "\n" << futureLambda.get() << std::endl; std::cout << std::endl; } |
The program execution is not so exciting.
The future gets a function (line 23), a function object (line 27), and a lambda function (line 30). In the end, each future requests its value (line 32).
And again, a little bit more formal. The std::async calls in lines 23, 27, and 30 create a data channel between the two endpoints’ future and promise. The promise immediately starts to execute its work package. But that is only the default behavior. By the get call, the future requests the result of Its work packages.
Eager or lazy evaluation
Eager or lazy evaluation are two orthogonal strategies to calculate the result of an expression. In the case of eager evaluation, the expression will immediately be evaluated; in the case of lazy evaluation, the expression will only be evaluated if needed. Often lazy evaluation is called call-by-need. With lazy evaluation, you save time and compute power because there is no evaluation on suspicion. An expression can be a mathematical calculation, a function, or a std::async call.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
By default, std::async executed its work package immediately. The C++ runtime decides if the calculation happens in the same or a new thread. With the flag std::launch::async std::async will run its work package in a new thread. In opposition to that, the flag std::launch::deferred expresses that std::async runs in the same thread. The execution is, in this case, lazy. That implies that the eager evaluations start immediately, but the lazy evaluation with the policy std::launch::deferred starts when the future asks for the value with its get call.
The program shows different behavior.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
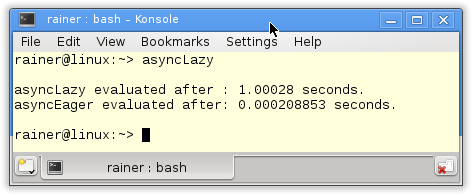
// asyncLazy.cpp #include <chrono> #include <future> #include <iostream> int main(){ std::cout << std::endl; auto begin= std::chrono::system_clock::now(); auto asyncLazy=std::async(std::launch::deferred,[]{ return std::chrono::system_clock::now();}); auto asyncEager=std::async( std::launch::async,[]{ return std::chrono::system_clock::now();}); std::this_thread::sleep_for(std::chrono::seconds(1)); auto lazyStart= asyncLazy.get() - begin; auto eagerStart= asyncEager.get() - begin; auto lazyDuration= std::chrono::duration<double>(lazyStart).count(); auto eagerDuration= std::chrono::duration<double>(eagerStart).count(); std::cout << "asyncLazy evaluated after : " << lazyDuration << " seconds." << std::endl; std::cout << "asyncEager evaluated after: " << eagerDuration << " seconds." << std::endl; std::cout << std::endl; } |
Both std::async calls (lines 13 and 15) return the current time point. But the first call is lazy, the second greedy. The short sleep of one second in line 17 makes that obvious. By the call asyncLazy.get() in line 19, the result will be available after a short nap. This is not true for asyncEager. asyncEager.get() gets the result from the immediately executed work package.
A bigger computing job
std::async is quite convenient to put a bigger compute job on more shoulders. So, the scalar product is calculated in the program with four asynchronous function calls.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
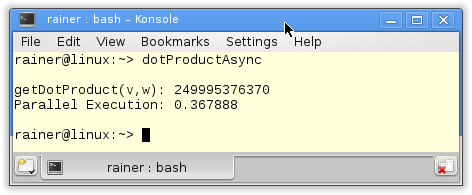
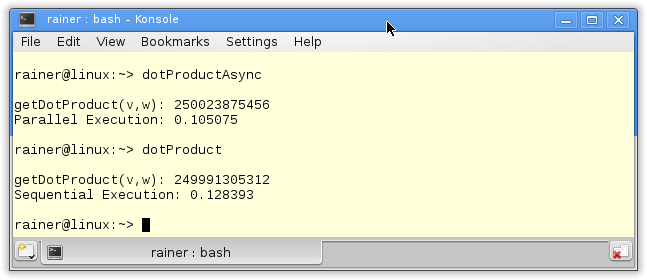
// dotProductAsync.cpp #include <chrono> #include <iostream> #include <future> #include <random> #include <vector> #include <numeric> static const int NUM= 100000000; long long getDotProduct(std::vector<int>& v, std::vector<int>& w){ auto future1= std::async([&]{return std::inner_product(&v[0],&v[v.size()/4],&w[0],0LL);}); auto future2= std::async([&]{return std::inner_product(&v[v.size()/4],&v[v.size()/2],&w[v.size()/4],0LL);}); auto future3= std::async([&]{return std::inner_product(&v[v.size()/2],&v[v.size()*3/4],&w[v.size()/2],0LL);}); auto future4= std::async([&]{return std::inner_product(&v[v.size()*3/4],&v[v.size()],&w[v.size()*3/4],0LL);}); return future1.get() + future2.get() + future3.get() + future4.get(); } int main(){ std::cout << std::endl; // get NUM random numbers from 0 .. 100 std::random_device seed; // generator std::mt19937 engine(seed()); // distribution std::uniform_int_distribution<int> dist(0,100); // fill the vectors std::vector<int> v, w; v.reserve(NUM); w.reserve(NUM); for (int i=0; i< NUM; ++i){ v.push_back(dist(engine)); w.push_back(dist(engine)); } // measure the execution time std::chrono::system_clock::time_point start = std::chrono::system_clock::now(); std::cout << "getDotProduct(v,w): " << getDotProduct(v,w) << std::endl; std::chrono::duration<double> dur = std::chrono::system_clock::now() - start; std::cout << "Parallel Execution: "<< dur.count() << std::endl; std::cout << std::endl; } |
The program uses the functionality of the random and time library. Both libraries are part of C++11. The vectors v and w are created and filled with a random number in lines 27 – 43. Each vector gets (lines 40 – 43) a hundred million elements. dist(engine) in lines 41 and 42 generated random numbers uniformly distributed from 0 to 100. The current calculation of the scalar product takes place in the function getDotProduct (lines 12 – 20). std::async uses the standard template library algorithm std::inner_product internally. The return statement sums up the results of the futures.
It takes about 0.4 seconds to calculate the result on my PC.
But now the question is. How fast is the program if I executed it on one core? A slight modification of the function getDotProduct, and we know the truth.
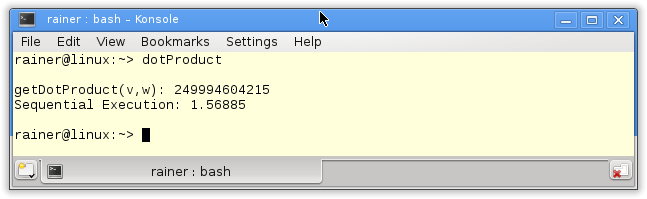
long long getDotProduct(std::vector<int>& v,std::vector<int>& w){ return std::inner_product(v.begin(),v.end(),w.begin(),0LL); }
The execution of the program is four times slower.
Optimization
But, if I compile the program with maximal optimization level O3 with my GCC, the performance difference is nearly gone. The parallel execution is about 10 percent faster.
What’s next?
In the next post, I will show you how to parallelize a big compute job by using std::packaged_task. (Proofreader Alexey Elymanov)
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org




Leave a Reply
Want to join the discussion?Feel free to contribute!