
Acquire-Release Fences
Acquire and release fences guarantee similar synchronization and ordering constraints as atomics with acquire-release semantics. Similar because the differences are in the details.
The most apparent difference between acquire and release memory barriers (fences) and atomics with acquire-release semantics is that memory barriers need no operations on atomics. But there is a more subtle difference. The acquire and release memory barriers are more heavyweight.
Atomic operations versus memory barriers
To simplify my writing job, I will now speak of acquire operations if I use memory barriers or atomic operations with acquire semantics. The same will hold for release operations.
The key idea of an acquire and a release operation is that it establishes synchronizations and ordering constraints between threads. This will also hold for atomic operations with relaxed semantic or non-atomic operations. So you see, the acquire and release operations come in pairs. In addition, the operations on atomic variables with acquire-release semantic must hold that these act on the same atomic variable. Said that I will, in the first step, look at these operations in isolation.
I start with the acquire operation.
Acquire operation
A read operation on an atomic variable attached with std::memory_order_acquire is an acquire operation.
In opposite to that, there is the std::atomic_thread_fence with acquire semantics.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.

This comparison emphasises two points.
- A memory barrier with acquire semantics establishes stronger ordering constraints. Although the acquire operation on an atomic and a memory barrier requires that no read or write operation can be moved before the acquire operation, there is an additional guarantee with the acquire memory barrier. No read operation can be moved after the acquire memory barrier.
- The relaxed semantic is sufficient for the reading of the atomic variable var. The std::atomc_thread_fence(std::memory_order_acquire) ensures that this operation can not be moved after the acquire fence.
The similar statement holds for the release memory barrier.
Release operation
The write operation on an atomic variable attached to the memory model std::memory_order_release is a release operation.

And further the release memory barrier.

In addition to the release operation on an atomic variable var, the release barrier guarantees two points:
- Store operations can’t be moved before the memory barrier.
- It’s sufficient for the variable var to have relaxed semantics.
If you want a simple overview of memory barriers, please read the last post in this blog. But now, I want to go one step further and build a program out of the presented components.
Synchronization with atomic operations versus memory barriers
I implement it as a starting point for comparing a typical consumer-producer workflow with acquire-release semantics. I will do this job with atomics and memory barriers.
Let’s start with atomics because most of us are comfortable with them. That will not hold for memory barriers. They are almost completely ignored in the literature on the C++ memory model.
Atomic operations
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
// acquireRelease.cpp #include <atomic> #include <thread> #include <iostream> #include <string> std::atomic<std::string*> ptr; int data; std::atomic<int> atoData; void producer(){ std::string* p = new std::string("C++11"); data = 2011; atoData.store(2014,std::memory_order_relaxed); ptr.store(p, std::memory_order_release); } void consumer(){ std::string* p2; while (!(p2 = ptr.load(std::memory_order_acquire))); std::cout << "*p2: " << *p2 << std::endl; std::cout << "data: " << data << std::endl; std::cout << "atoData: " << atoData.load(std::memory_order_relaxed) << std::endl; } int main(){ std::cout << std::endl; std::thread t1(producer); std::thread t2(consumer); t1.join(); t2.join(); delete ptr; std::cout << std::endl; } |
I hope this program looks familiar to you. That is the classic that I used in the post to memory_order_consume. The graphic directly explains why the consumer thread t2 sees all values from the producer thread t1.
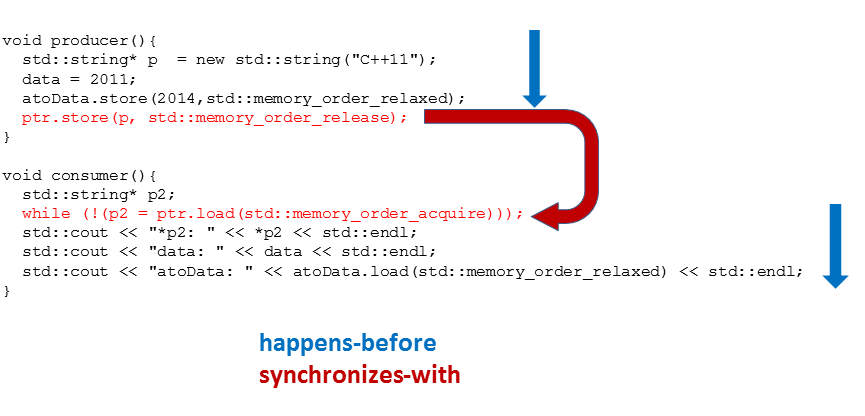
The program is well-defined, because the happens-before relation is transitive. I have only to combine the three happens-before relations:
- Line 13 – 15 happens-before line 16 (ptr.store(p,std::memory_order_release).
- Line 21 while(!(p2= ptrl.load(std::memory_order_acquire))) happens-before lines 22 – 24.
- Line 16 synchronizes-with line 21. => Line 16 happens-before line 21.
But now the story gets more thrilling. How can I adjust the workflow to memory barriers?
Memory barriers
It’s straightforward to port the program to memory barriers.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
// acquireReleaseFences.cpp #include <atomic> #include <thread> #include <iostream> #include <string> std::atomic<std::string*> ptr; int data; std::atomic<int> atoData; void producer(){ std::string* p = new std::string("C++11"); data = 2011; atoData.store(2014,std::memory_order_relaxed); std::atomic_thread_fence(std::memory_order_release); ptr.store(p, std::memory_order_relaxed); } void consumer(){ std::string* p2; while (!(p2 = ptr.load(std::memory_order_relaxed))); std::atomic_thread_fence(std::memory_order_acquire); std::cout << "*p2: " << *p2 << std::endl; std::cout << "data: " << data << std::endl; std::cout << "atoData: " << atoData.load(std::memory_order_relaxed) << std::endl; } int main(){ std::cout << std::endl; std::thread t1(producer); std::thread t2(consumer); t1.join(); t2.join(); delete ptr; std::cout << std::endl; } |
The first step is to insert just in place of the operations with acquire and release semantic the corresponding memory barriers with acquire and release semantics (lines 16 and 23). In the next step, I change the atomic operations with acquire or release semantics to relaxed semantics (lines 17 and 22). That was already mechanical. Of course, I can only replace one acquire or release operation with the corresponding memory barrier. The key point is that the release operation establishes with the acquire operation a synchronize-with relation and, therefore, a happens-before relation.
For the more visual reader, the whole description in a picture.

The key question is. Why do the operations after the acquire memory barrier sees the effects of the operations before the release memory barrier? Because data is a non-atomic variable and atoData is used with relaxed semantics, both can be reordered. But that’s not possible. The std::atomic_thread_fence(std::memory_order_release) as a release operation in combination with the std::atomic_thread_fence(std::memory_order_acquire) forbids the partial reordering. To follow my reasoning in detail, read the analysis of the memory barriers at the beginning of the post.
For clarity, the whole reasoning is to the point.
- The acquire and release memory barriers prevent the reordering of the atomic and non-atomic operations across the memory barriers.
- The consumer thread t2 is waiting in the while (!(p2= ptr.load(std::memory_order_relaxed))) loop until the pointer ptr.stor(p,std::memory_order_relaxed) is set in the producer thread t1.
- The release memory barrier synchronizes-with the acquire memory barrier.
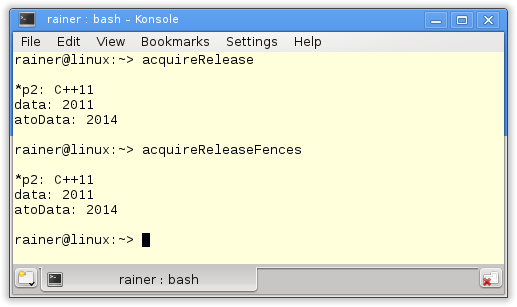
Finally, the output of the programs.
What’s next?
But now, to the weakest memory model. The relaxed semantics will be the topic of the next post. There are no ordering constraints.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org






Leave a Reply
Want to join the discussion?Feel free to contribute!