
A Lock-Free Stack: A Simplified Implementation
Today, I continue my mini story about lock-free data structures.
General Considerations
From the outside, the caller’s responsibility (application) is to protect the data. From inside, the data structure is responsible for protecting itself. A data structure that protects itself so a data race cannot appear is called thread-safe.
First, what general considerations must you keep in mind when designing a concurrent data structure?
- Locking Strategy: Should the data structure support coarse-grained or fine-grained locking or be lock-free? Coarse-grained locking might be easier to implement but introduces contention. A fine-grained implementation or a lock-free one is much more challenging. First of all, what do I mean by coarse-grained locking? Coarse-grained locking means that only one thread uses the data structure at one point in time.
- The Granularity of the Interface: The bigger the thread-safe data structure’s interface, the more difficult it becomes to reason about its concurrent usage.
- Typical Usage Pattern: When readers mainly use your data structure, you should not optimize it for writers.
- Avoidance of Loopholes: Don’t pass the internals of your data structure to clients.
- Contention: Do concurrent client requests seldom or often use your data structure?
- Scalability: How is your data structure’s performance characteristic when the number of
concurrent clients increases, or the data structure is bounded? - Invariants: Which invariant must hold for your data structure when used?
- Exceptions: What should happen if an exception occurs?
Of course, these considerations are dependent on each other. For example, using a coarse-grained locking strategy may increase the contention on the data structure and break scalability.
First of all, what is a stack?
A Stack
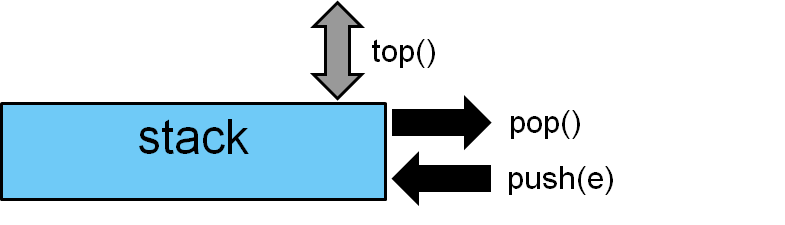
And std::stack follows the LIFO principle (Last In – First Out). A stack sta, which needs the header <stack>, has three member functions.
With sta.push(e), you can insert a new element e at the top of the stack, remove it from the top with sta.pop() , and reference it with sta.top(). The stack supports the comparison operators and knows its size.
#include <stack> ... std::stack<int> myStack; std::cout << myStack.empty() << '\n'; // true std::cout << myStack.size() << '\n'; // 0 myStack.push(1); myStack.push(2); myStack.push(3); std::cout << myStack.top() << '\n'; // 3 while (!myStack.empty()){ std::cout << myStack.top() << " "; myStack.pop(); } // 3 2 1 std::cout << myStack.empty() << '\n'; // true std::cout << myStack.size() << '\n'; // 0
Now, let me start with the implementation of a lock-free stack.
A Simplified Implementation
In my simplified implementation, I start with the push member function. First, let me visualize how a new node is added to a singly-linked list. head is the pointer to the first node in the singly-linked list.
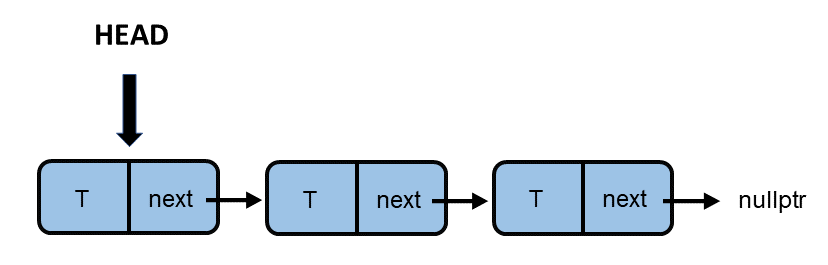
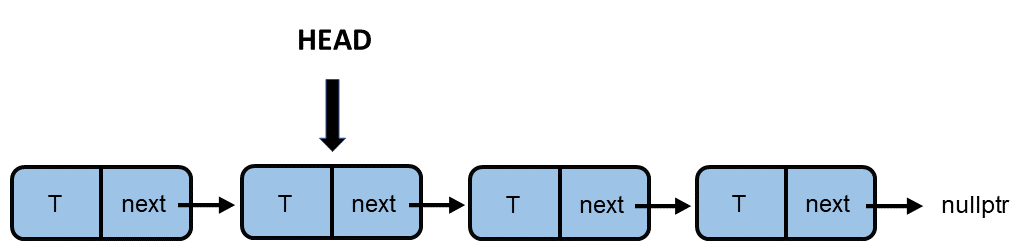
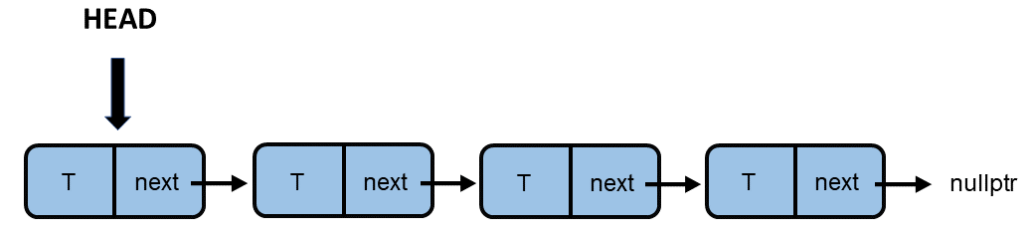
Each node in the singly-linked list has two attributes. Its value T and the next. next points to the next element in the singly-linked list. Only the node points to the nullptr. Adding a new node to the data is straightforward. Create a new node and let next pointer point to the previous head. So far, the new node is not accessible. Finally, the new node becomes the new head, completing the push operation.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
The following example shows the lock-free implementation of a concurrent stack.
// lockFreeStackPush.cpp #include <atomic> #include <iostream> template<typename T> class LockFreeStackPush { private: struct Node { T data; Node* next; Node(T d): data(d), next(nullptr) {} }; std::atomic<Node*> head; public: LockFreeStackPush() = default; LockFreeStackPush(const LockFreeStackPush&) = delete; LockFreeStackPush& operator= (const LockFreeStackPush&) = delete; void push(T val) { Node* const newNode = new Node(val); // 1 newNode->next = head.load(); // 2 while( !head.compare_exchange_strong(newNode->next, newNode) ); // 3 } }; int main(){ LockFreeStackPush<int> lockFreeStack; lockFreeStack.push(5); LockFreeStackPush<double> lockFreeStack2; lockFreeStack2.push(5.5); LockFreeStackPush<std::string> lockFreeStack3; lockFreeStack3.push("hello"); }
Let me analyze the crucial member function push. It creates the new node (line 1), adjusts
its next pointer to the old head, and makes the new node in a so-called CAS operation the new head (line 3). A CAS operation provides, in an atomic step, a compare and swap operation.
The call newNode->next = head.load() loads the old value of head. If the loaded value newNode->next is still the same such as head in line 3, the head is updated to the newNode, and the call head.compare_exchange_strong returns true. If not, the call returns false, and the while loop is executed until the call returns true. head.compare_exchange_strong returns false if another thread has meanwhile added a new node to the stack.
Lines 2 and 3 build a kind of atomic transaction. First, you make a snapshot of the data structure (line 2), then try to publish the transaction (line 3). If the snapshot is no longer valid, you roll back and try it again.
What’s Next?
Todays simplified stack implementation serves me as a baseline for upcoming stacks.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org




