A Lock-Free Stack: Atomic Smart Pointer
The easiest way to solve this memory leak issue from the last post is to use a std::shared_ptr.
Atomic Smart Pointer
There are two ways to apply atomic operations on a std::shared_ptr: In C++11, you can use the free atomic functions on std::shared_ptr. With C++20, you can use atomic smart pointers.
C++11
Using atomic operations on std::shared_ptr is tedious and error-prone. You can easily forget the atomic operations, and all bets are open. The following example shows a lock-free stack based on std::shared_ptr.
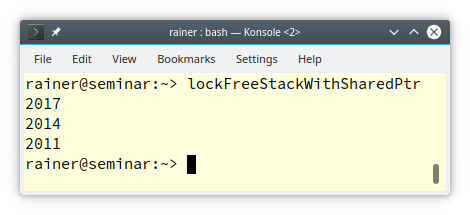
// lockFreeStackWithSharedPtr.cpp #include <atomic> #include <future> #include <iostream> #include <stdexcept> #include <memory> template<typename T> class LockFreeStack { public: struct Node { T data; std::shared_ptr<Node> next; }; std::shared_ptr<Node> head; public: LockFreeStack() = default; LockFreeStack(const LockFreeStack&) = delete; LockFreeStack& operator= (const LockFreeStack&) = delete; void push(T val) { auto newNode = std::make_shared<Node>(); newNode->data = val; newNode->next = std::atomic_load(&head); // 1 while( !std::atomic_compare_exchange_strong(&head, &newNode->next, newNode) ); // 2 } T topAndPop() { auto oldHead = std::atomic_load(&head); // 3 while( oldHead && !std::atomic_compare_exchange_strong(&head, &oldHead, std::atomic_load(&oldHead->next)) ) { // 4 if ( !oldHead ) throw std::out_of_range("The stack is empty!"); } return oldHead->data; } }; int main(){ LockFreeStack<int> lockFreeStack; auto fut = std::async([&lockFreeStack]{ lockFreeStack.push(2011); }); auto fut1 = std::async([&lockFreeStack]{ lockFreeStack.push(2014); }); auto fut2 = std::async([&lockFreeStack]{ lockFreeStack.push(2017); }); auto fut3 = std::async([&lockFreeStack]{ return lockFreeStack.topAndPop(); }); auto fut4 = std::async([&lockFreeStack]{ return lockFreeStack.topAndPop(); }); auto fut5 = std::async([&lockFreeStack]{ return lockFreeStack.topAndPop(); }); fut.get(), fut1.get(), fut2.get(); std::cout << fut3.get() << '\n'; std::cout << fut4.get() << '\n'; std::cout << fut5.get() << '\n'; }
This lock-free stack implementation is quite similar to the previous one without memory reclamation. The main difference is that the nodes are of type std::shared_ptr. All operations std::shared_ptr are done atomically by using the free atomic operations std::load (lines 1 and 4), and std::atomic_compare_exchange_strong (lines 2 and 3). The free atomics operations require a pointer. I want to emphasize explicitly, the read operation of the next node in oldHead->next (line 4) must be atomic because oldHead->next can be used by other threads.
Finally, here is the output of the program.
Let’s jump nine years into the future and use C++20.
C++20
C++20 supports partial specializations of std::atomic for std::shared_ptr and std::weak_ptr. The following implementation puts the nodes of the lock-free stack into a std::atomic<std::shared_ptr<Node>>.
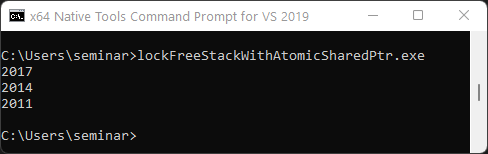
// lockFreeStackWithAtomicSharedPtr.cpp #include <atomic> #include <future> #include <iostream> #include <stdexcept> #include <memory> template<typename T> class LockFreeStack { private: struct Node { T data; std::shared_ptr<Node> next; }; std::atomic<std::shared_ptr<Node>> head; // 1 public: LockFreeStack() = default; LockFreeStack(const LockFreeStack&) = delete; LockFreeStack& operator= (const LockFreeStack&) = delete; void push(T val) { // 2 auto newNode = std::make_shared<Node>(); newNode->data = val; newNode->next = head; while( !head.compare_exchange_strong(newNode->next, newNode) ); } T topAndPop() { auto oldHead = head.load(); while( oldHead && !head.compare_exchange_strong(oldHead, oldHead->next) ) { if ( !oldHead ) throw std::out_of_range("The stack is empty!"); } return oldHead->data; } }; int main(){ LockFreeStack<int> lockFreeStack; auto fut = std::async([&lockFreeStack]{ lockFreeStack.push(2011); }); auto fut1 = std::async([&lockFreeStack]{ lockFreeStack.push(2014); }); auto fut2 = std::async([&lockFreeStack]{ lockFreeStack.push(2017); }); auto fut3 = std::async([&lockFreeStack]{ return lockFreeStack.topAndPop(); }); auto fut4 = std::async([&lockFreeStack]{ return lockFreeStack.topAndPop(); }); auto fut5 = std::async([&lockFreeStack]{ return lockFreeStack.topAndPop(); }); fut.get(), fut1.get(), fut2.get(); std::cout << fut3.get() << '\n'; std::cout << fut4.get() << '\n'; std::cout << fut5.get() << '\n'; }
The main difference between the previous and this implementation is that the Node is embedded into a std::atomic<std::shared_ptr<Node>> (line 1). Consequentially, the member function push (line 2) creates a std::shared_ptr<Node> and the call head.load() in the member function topAndPop returns a std::atomic<std::shared_ptr<Node>>.
Here is the output of the program.
std::atomic<std::shared_ptr> is not Lock-Free
Honestly, I cheated in the previous programs using atomic operations on a std::shared_ptr and a std::atomic. Those atomic operations on a std::shared_ptr are currently not lock-free. Additionally, an implementation of std::atomic can use a locking mechanism to support all partial and full specializations of std::atomic.
The call atom.lock_free() on a std::atomic<std::shared_ptr<Node>> returns false.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
// atomicSmartPointer.cpp #include <atomic> #include <iostream> #include <memory> template <typename T> struct Node { T data; std::shared_ptr<Node> next; }; int main() { std::cout << '\n'; std::cout << std::boolalpha; std::atomic<std::shared_ptr<Node<int>>> node; std::cout << "node.is_lock_free(): " << node.is_lock_free() << '\n'; std::cout << '\n'; }
What’s Next?
So, we are back to square one and need to worry about memory management in my next post.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org