
C++ Parallel STL Benchmark
Today, I’m happy to present a guest post from Victor J. Duvanenko about my favorite C++17 feature: the parallel STL algorithms.
Victor has published a book about “Practical Parallel Algorithms in C++ and C#“. Without further ado, here is Victor guest post:
C++ includes a standard set of generic algorithms, called STL (Standard Template Library). On Windows, Microsoft provides parallel versions of these algorithms, listed below with the first argument being std::. Also, Intel provides parallel implementations, listed below with the first argument being dpl::. These parallel versions utilize multiple cores of the processor, providing substantially faster performance for many of the standard algorithms.
Specifying a single-core or multi-core versions of algorithms is simple, as demonstrated below:
sort(data.begin(), data.end()); // single-core // or sort(std::execution::seq, data.begin(), data.end()); // single-core // Parallel multi-core sort(std::execution::par, data.begin(), data.end()); // multi-core
The first two calls to “sort()” are equivalent, running on a single-core of the processor. The last call to “sort()” utilizes multiple cores. Four algorithm execution variations are:
seq – sequential single-core version
unseq – single-core SIMD/SSE vectorized
par – multi-core version
par_unseq – multi-core SIMD/SSE vectorized
The following Table shows algorithms which show the highest level of parallel speedup when run on a 14-core i7-12700 laptop processor, processing an array of 100 Million 32-bit integers:
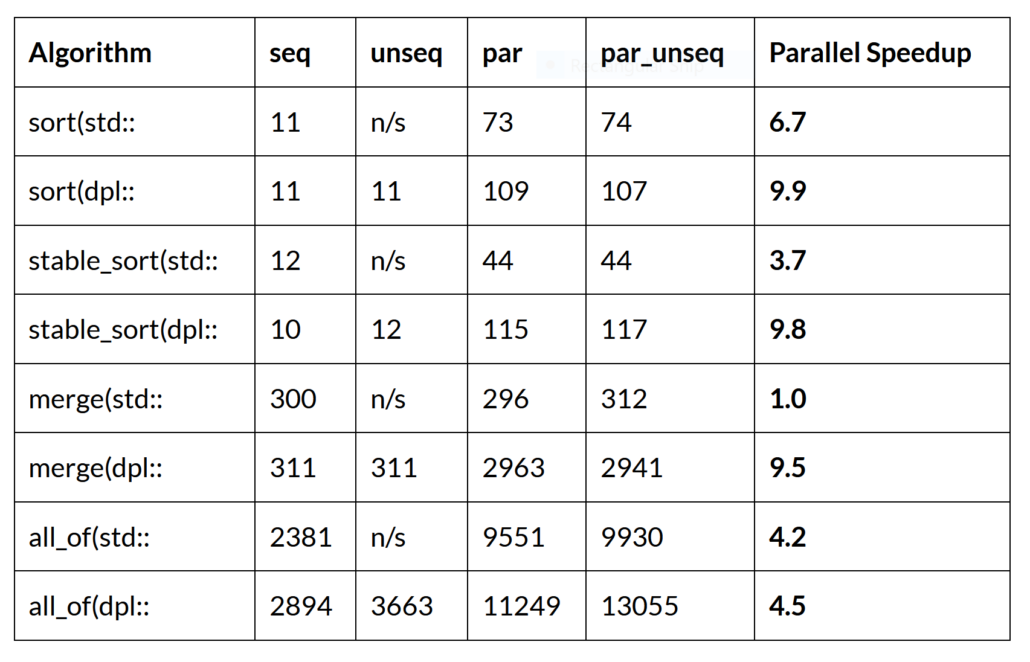
n/s – not supported – i.e. variation not implemented.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
Benchmarks on a processor with 48 cores will be shown later. The units for each item in the Table are millions of integers per second. For instance, for “sort(std::” par version runs at 73 million integers/second, and “sort(dpl::” par version runs at 109 million integers/second. Each column shows performance of one of the four implementations. Array size of 100 million was chosen to eliminate caching effects, where the array is too big to fit into the cache of the processor to measure the parallel speedup for the use case of a very large array.
Benchmark Environment
The above benchmarks were performed using VisualStudio 2022 built in release mode using Intel C++ compiler and Intel OneAPI 2023.1 environment. This enabled access to both Microsoft std:: implementations and Intel dpl:: implementations. Benchmarks were run on Windows 11.
Observations
Not all standard functions are implemented by Microsoft or Intel.
Microsoft does not support sequential-SIMD (unseq) implementation for many algorithms, where this implementation does not compile. For other algorithms, Microsoft implementations compile, but do not provide performance advantage, as stated in this blog.
Intel implements more parallel algorithms with higher performance for most, except count (on 48-core). Parallel functions experience parallel scaling as core count grows. All algorithms accelerate when running on multiple cores.
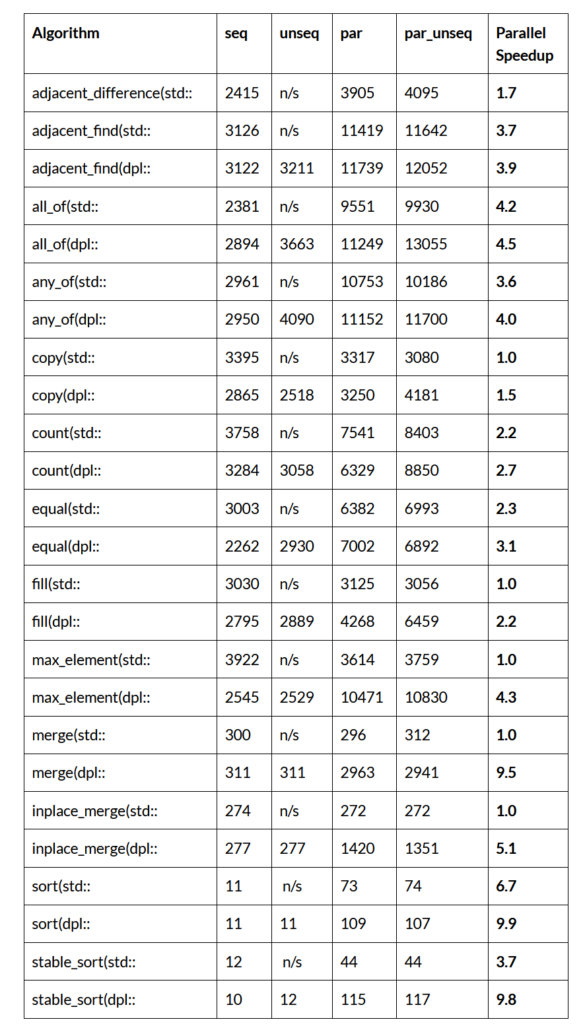
More Standard Parallel Algorithms
Table below provides benchmarks for single-core and multicore implementations of standard C++ algorithms on the 14-core laptop processor:
More Cores, More Performance
Some of the standard C++ algorithms scale better than others as the number of processor cores increases. The following Table shows performance of single-core serial and multi-core parallel algorithms on a 48-core Intel Xeon 8275CL AWS node when processing an array of 100 Million 32-bit integers:
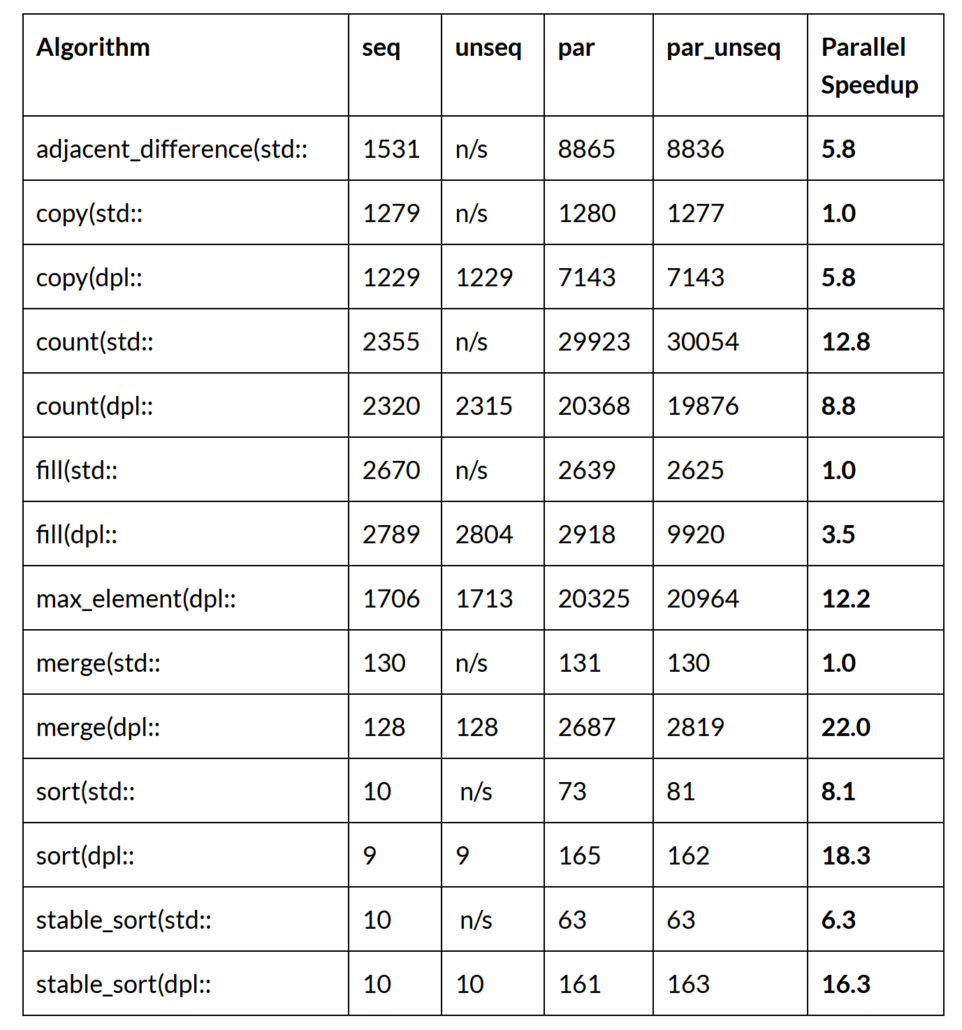
Every parallel algorithm accelerates more with more cores and higher memory bandwidth available on the 48-core processor. For large problems parallel algorithm implementations provide a substantial performance benefit.
Nvidia Parallel Algorithms
Nvidia has developed C++ Parallel STL implementation for the nvc++ compiler, which can run on x86 instruction set processors such as those by Intel and AMD. The following Table will be updated shortly for compilation of the benchmark with “-stdpar=multicore”:
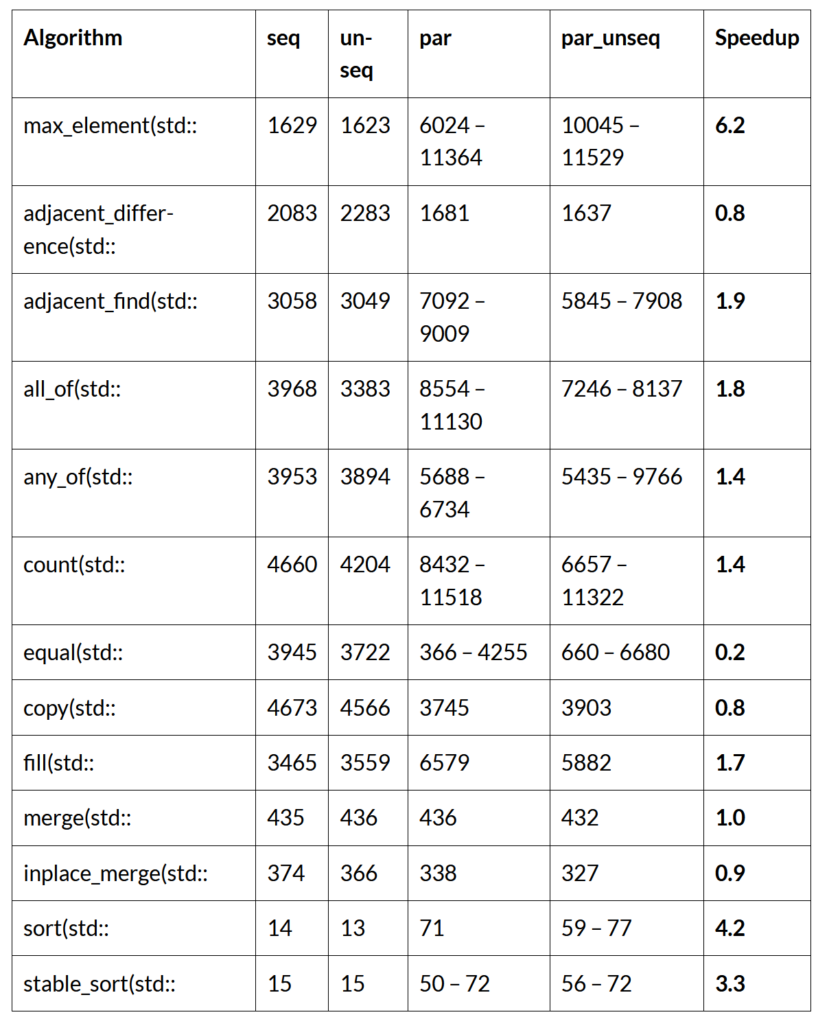
Nvidia’s parallel implementations show significant variation in performance compared to Intel’s and Microsoft’s. Nvidia also supports accelerating standard C++ algorithms using GPUs. See benchmarks in this blog.
Benchmark Code
Source code for the benchmark implementation is freely available in this repository:
https://github.com/DragonSpit/ParallelSTL
Your Own Higher Performance Algorithms
If you want to roll your own parallel algorithms, the following book shows by example how to do it. For instance, standard algorithms implement comparison-based sorting only. Parallel Linear-Time Radix Sort, developed in the book, raises performs many times higher. Several strategies to simplify parallel programing are demonstrated with all source code freely available in a repository:
What’s next?
In my next post, I continue my journey through C++23. This time, I will write about std::expected.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org








