Buckets, Capacity, and Load Factor
The hash function maps a potentially infinite number of keys on a finite number of buckets. What is the strategy of the C++ runtime and how can you tailor it to your needs, that is what this article is all about.
In order not to lose the big picture I want to explicitly stress the point. This article is about std::unordered_set but observations hold also for the other three unordered associative containers in C++11. If you want to have a closer look, you should read my previous post Hash tables.
Rehashing
The hash function decides to which bucket the key goes. Because the hash function reduces a potentially infinite number of keys on a finite number of buckets, various keys may go to the same bucket. This event is called a collision. The keys in each bucket are typically stored as a singly linked list. With this knowledge in mind, you can quite simply reason how fast the access time on a key is in an unordered associative container. The application of the hash function is a constant operation; the search of the key in the singly linked list is a linear operation. Therefore, the goal of the hash function is to produce few collisions.
The number of buckets is called the capacity, and the average number of elements of each bucket is the load factor. The C++ runtime creates, by default, new buckets if the load factor goes beyond 1. This process is called rehashing and you can explicitly trigger it by setting the capacity of the unordered associative container to a higher value. Once more, the few new terms are on the spot.
- Capacity: Number of buckets
- Load factor: Average number of elements (keys) per bucket
- Rehashing: Creation of new buckets
You can read and adjust these characteristics.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
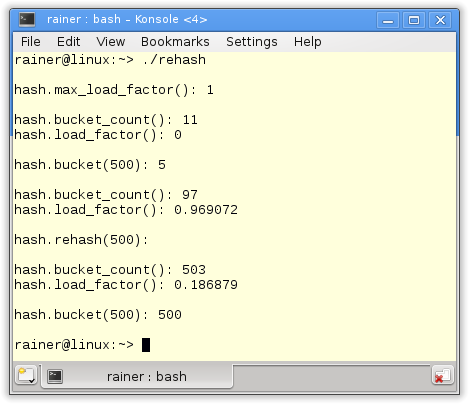
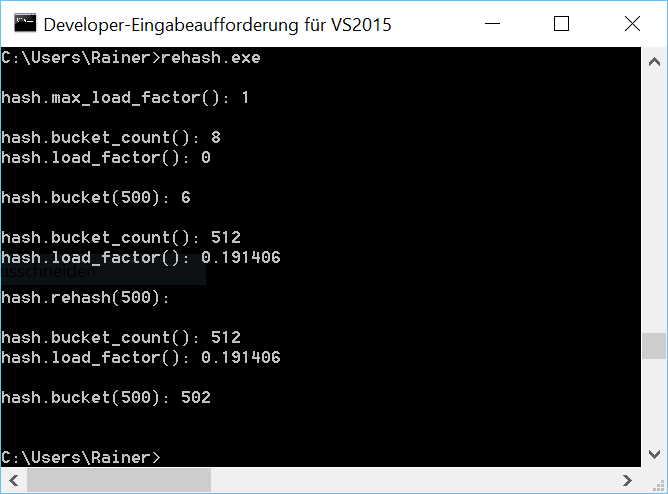
// rehash.cpp #include <iostream> #include <random> #include <unordered_set> void getInfo(const std::unordered_set<int>& hash){ std::cout << "hash.bucket_count(): " << hash.bucket_count() << std::endl; std::cout << "hash.load_factor(): " << hash.load_factor() << std::endl; } void fillHash(std::unordered_set<int>& h,int n){ std::random_device seed; // default generator std::mt19937 engine(seed()); // get random numbers 0 - 1000 std::uniform_int_distribution<> uniformDist(0,1000); for ( int i=1; i<= n; ++i){ h.insert(uniformDist(engine)); } } int main(){ std::cout << std::endl; std::unordered_set<int> hash; std::cout << "hash.max_load_factor(): " << hash.max_load_factor() << std::endl; std::cout << std::endl; getInfo(hash); std::cout << std::endl; // only to be sure hash.insert(500); // get the bucket of 500 std::cout << "hash.bucket(500): " << hash.bucket(500) << std::endl; std::cout << std::endl; // add 100 elements fillHash(hash,100); getInfo(hash); std::cout << std::endl; // at least 500 buckets std::cout << "hash.rehash(500): " << std::endl; hash.rehash(500); std::cout << std::endl; getInfo(hash); std::cout << std::endl; // get the bucket of 500 std::cout << "hash.bucket(500): " << hash.bucket(500) << std::endl; std::cout << std::endl; } |
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
At first to the helper functions getInfo (lines 7 – 10) and fillHash (lines 12 – 22). The function getInfo returns for the std::unordered_set the number of buckets and the load factor. The function fillHash fills the unordered associative container with n arbitrarily created integers.
It is interesting to compare the execution of the program on Linux and Windows. I used on Linux the GCC; I used on Windows the cl.exe compiler. I translated the program without optimization.
At first, I’m interested in the empty container’s maximum load factor (line 29). If the std::unordered_set exceeds the maximum load factor, a rehashing will take place. The maximum load factor is 1. The GCC initially starts with 11 buckets, Windows starts with 8 buckets. Of course, the load factor is 0. Putting the key 500 (line 38) into the hash table will go to bucket five on Linux and to bucket six on Windows. In line 45, I added 100 keys to the hash table. Afterward, Linux has 97, and Windows has 512 buckets. Linux has less than 100 buckets because I got a few identical keys. Linux now has a load factor near 1, but Windows is about 0.2. Therefore, I can put a lot more elements into the Windows hash table without the need for rehashing. I trigger the rehashing on Linux by requesting at least 500 buckets (line 51). Here you see the difference. On Linux, I get new buckets, and the keys must be newly distributed. But this is not happening on Windows because 512 is bigger than 500. In the end, the key 500 (line 61) is in a different bucket.
It isn’t easy to conclude the observed behavior on Linux and Windows. In the unoptimized case, it seems that Linux optimizes memory consumption and Windows for performance. But I want to give one piece of advice for using unordered associative containers.
My rule of thumb
If you know how large your unordered associative container will become, start with a reasonable number of buckets. Therefore, you can spare a lot of expensive rehashings because each rehashing includes memory allocation and the new distribution of all keys. The question is, what is reasonable? My rule of thumb is to start with a bucket size similar to the number of your keys. Therefore, your load factor is close to 1.
I’m looking forward to a discussion about my rule of thumb. If possible, I will add them to this post.
What’s next?
POD’s stands for Plain Old Data. These are data types that have a C standard layout. Therefore, you can directly manipulate them with the C functions memcpy, memmove, memcmp, or memset. With C++11 even instances of classes can be PODs. I will write in the next post, about which requirements must hold for the class.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org






Leave a Reply
Want to join the discussion?Feel free to contribute!