Type-Traits: Performance Matters
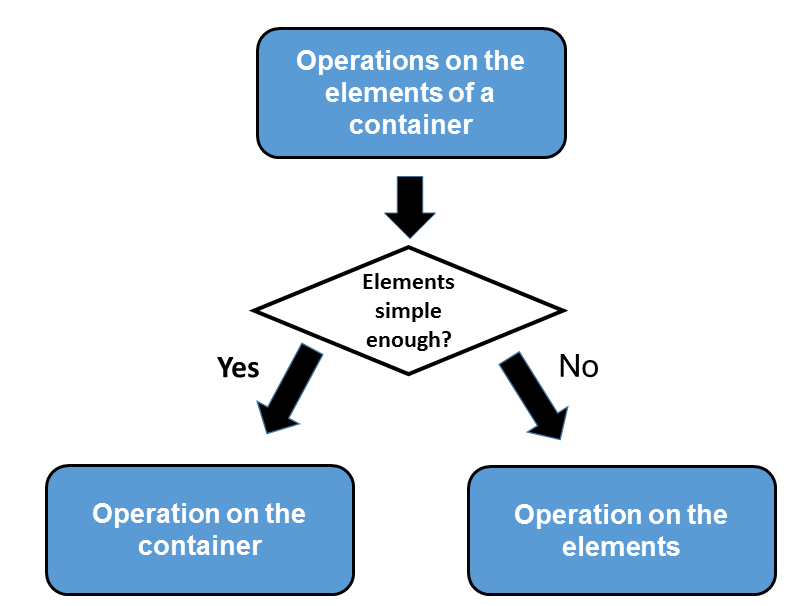
If you look carefully, you see type-traits have a big optimization potential. The type-traits support the first step to analyze the code at the compile-time and, in the second step, to optimize the code based on that analysis. How is that possible? Dependent on the type of variable, a faster variant of an algorithm will be chosen.
Work on the entire memory area
The idea is quite straightforward and is used in current Standard Template Library implementations (STL) implementations. If the elements of a container are simple enough, the algorithm of the STL, like std::copy, std::fill, or std::equal will directly be applied to the memory area. Instead of using std::copy to copy the elements individually, all is done in one large step. Internally, C functions like memcmp, memset, memcpy, or memmove are used. The small difference between memcpy and memmove is that memmove can deal with overlapping memory areas.
The implementations of the algorithm std::copy, std::fill, or std::equal use a simple strategy. std::copy is like a wrapper. This wrapper checks if the element is simple enough. If so, the wrapper will delegate the work to the optimized copy function. If not, the general copy algorithm will be used. This one copies each element after the other. If the elements are simple enough, the functions of the type-traits library will be used to make the right decision.
The graphic shows this strategy once more:
That was the theory, but here is the practice. Which strategy is used by std::fill?
std::fill
std::fill assigns each element in the range a value. The listing shows a simple implementation.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
// fill.cpp #include <cstring> #include <chrono> #include <iostream> #include <type_traits> namespace my{ template <typename I, typename T, bool b> void fill_impl(I first, I last, const T& val, const std::integral_constant<bool, b>&){ while(first != last){ *first = val; ++first; } } template <typename T> void fill_impl(T* first, T* last, const T& val, const std::true_type&){ std::memset(first, val, last-first); } template <class I, class T> inline void fill(I first, I last, const T& val){ // typedef std::integral_constant<bool,std::has_trivial_copy_assign<T>::value && (sizeof(T) == 1)> boolType; typedef std::integral_constant<bool,std::is_trivially_copy_assignable<T>::value && (sizeof(T) == 1)> boolType; fill_impl(first, last, val, boolType()); } } const int arraySize = 100000000; char charArray1[arraySize]= {0,}; char charArray2[arraySize]= {0,}; int main(){ std::cout << std::endl; auto begin= std::chrono::system_clock::now(); my::fill(charArray1, charArray1 + arraySize,1); auto last= std::chrono::system_clock::now() - begin; std::cout << "charArray1: " << std::chrono::duration<double>(last).count() << " seconds" << std::endl; begin= std::chrono::system_clock::now(); my::fill(charArray2, charArray2 + arraySize, static_cast<char>(1)); last= std::chrono::system_clock::now() - begin; std::cout << "charArray2: " << std::chrono::duration<double>(last).count() << " seconds" << std::endl; std::cout << std::endl; } |
my::fill make in line 27 the decision which implementation of my::fill_impl is applied. To use the optimized variant, the elements should have a compiler-generated copy assignment operator std::is_trivially_copy_assignable<T> and should be 1 byte large: sizeof(T) == 1. The function std::is_trivially_copy_assignable is part of the type-traits. I explain in the post Check types the magic behind the type-traits functions.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
My GCC 4.8 calls instead of the function std::is_trivially_copy_assignable std::has_trivial_copy_assign. If you request the copy assignment operator with the keyword default from the compiler, the operator will be trivial.
struct TrivCopyAssign{ TrivCopyAssign& operator=(const TrivCopyAssign& other)= default; };
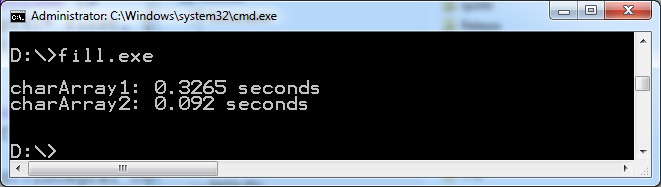
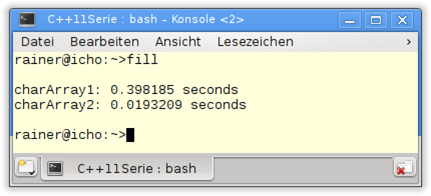
Back to the code example. If the expression boolType() in line 27 is true, the optimized version of my::fill_impl in lines 18 – 21 will be used. This variant fills in opposite to the generic variant my::fill_impl (line 10 -16) the entire memory area – consisting of 100 million entries – with the value 1. sizeof(char) is 1.
What about the performance of the program? I compiled the program without optimization. The execution of the optimized variant is about 3 times faster on windows; about 20 times faster on Linux.
Microsoft Visual 15
GCC 4.8
The decision of which variant of an algorithm should be used is sometimes not so easy to make.
std::equal
The implementer of std::equal had special humor because he called his decision criteria __simple. The code is copied from the GCC 4.8 STL implementation.
1 2 3 4 5 6 7 8 9 10 11 12 |
template<typename _II1, typename _II2> inline bool __equal_aux(_II1 __first1, _II1 __last1, _II2 __first2){ typedef typename iterator_traits<_II1>::value_type _ValueType1; typedef typename iterator_traits<_II2>::value_type _ValueType2; const bool __simple = ((__is_integer<_ValueType1>::__value || __is_pointer<_ValueType1>::__value ) && __is_pointer<_II1>::__value && __is_pointer<_II2>::__value &&__are_same<_ValueType1, _ValueType2>::__value ); return std::__equal<__simple>::equal(__first1, __last1, __first2); } |
I have a different perception of __simple. To use the optimized variant of std::equal, the container elements have to fulfil some assurances. The elements of the container have to be of the same type (line 9) and have to be an integral or a pointer (line 5 and 6). In addition, the iterators have to be pointers (lines 7 and 8).
What’s next?
They didn’t make it in the C++98 standard. But we have them in C++11: hash tables. The official name is an unordered associative container. Unofficially, they are often called dictionaries. They promise one important feature: performance because their access time is constant in the optimal case.
Why we need the unordered associative container? What makes them different from the C++98 ordered associate containers (std::map, std::set, std::multimap, and std::multiset)? That’s the story of the next post.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org




Leave a Reply
Want to join the discussion?Feel free to contribute!