
Dining Philosophers Problem I
At Christmas time, I had a few nice discussions with Andre Adrian. He solved the classical dining philosopher’s problem in various ways using modern C++. I convinced him to write an article about this classic synchronization issue, and I’m happy to publish it in three consecutive posts.
By Benjamin D. Esham / Wikimedia Commons, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=56559
Dining philosophers in C++ by Andre Adrian
Edsger W. Dijkstra described the dining philosophers’ problem. “Five philosophers, numbered from 0 through 4 are living in a house where the table laid for them, each philosopher having his place at the table: Their only problem -besides those of philosophy- is that the dish served is a very difficult kind of spaghetti, that has to be eaten with two forks. There are two forks next to each plate, so that presents no difficulty: as a consequence, however, no two neighbors may be eating simultaneously.” [ref 1971; Dijkstra; EWD310 Hierarchical Ordering of Sequential Processes; https://www.cs.utexas.edu/users/EWD/transcriptions/EWD03xx/EWD310.html]
We use the following problem description: 4 philosophers live a simple life. Every philosopher performs the same routine: he thinks for some random duration, gets his first fork, gets his second fork, eats for some random duration, puts down the forks, and starts thinking again. To make the problem interesting, the 4 philosophers have only 4 forks. Philosopher number 1 has to take forks number 1 and 2 for eating. Philosopher 2 needs forks 2 and 3, and so on, up to philosopher 4, who needs forks 4 and 1 for eating. After eating, the philosopher puts the forks back on the table.
Multiple Resource Use
From problem description to programming, we translate philosophers to threads and forks to resources. In our first program – dp_1.cpp – we create 4 “philosopher” threads and 4 “fork” resource integers.
 Modernes C++ Mentoring
Modernes C++ Mentoring
Do you want to stay informed: Subscribe.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
// dp_1.cpp #include <iostream> #include <thread> #include <chrono> int myrand(int min, int max) { return rand()%(max-min)+min; } void lock(int& m) { m=1; } void unlock(int& m) { m=0; } void phil(int ph, int& ma, int& mb) { while(true) { int duration=myrand(1000, 2000); std::cout<<ph<<" thinks "<<duration<<"ms\n"; std::this_thread::sleep_for(std::chrono::milliseconds(duration)); lock(ma); std::cout<<"\t\t"<<ph<<" got ma\n"; std::this_thread::sleep_for(std::chrono::milliseconds(1000)); lock(mb); std::cout<<"\t\t"<<ph<<" got mb\n"; duration=myrand(1000, 2000); std::cout<<"\t\t\t\t"<<ph<<" eats "<<duration<<"ms\n"; std::this_thread::sleep_for(std::chrono::milliseconds(duration)); unlock(mb); unlock(ma); } } int main() { std::cout<<"dp_1\n"; srand(time(nullptr)); int m1{0}, m2{0}, m3{0}, m4{0}; std::thread t1([&] {phil(1, m1, m2);}); std::thread t2([&] {phil(2, m2, m3);}); std::thread t3([&] {phil(3, m3, m4);}); std::thread t4([&] {phil(4, m4, m1);}); t1.join(); t2.join(); t3.join(); t4.join(); } |
The main() function establishes random numbers in line 42. We set the random number generator seed value to the number of seconds since 1st January 1970. We define our fork resources in line 44. Then we start four threads beginning in line 46. To avoid premature thread termination, we join the threads beginning in line 51. The thread function phil() has a forever loop. The while(true) statement is always true, therefore the thread will never terminate. The problem description says, “he thinks for some random duration”. First, we calculate a random duration with the function myrand(), see line 20 and line 6. The function myrand() produces a pseudo-random return value in the range of [min, max). For program trace, we log the philosopher’s number, his current state of “he thinks,” and the duration to the console. The sleep_for() statement lets the scheduler put the thread for the duration into the waiting state. In a “real” program application, source code uses up time instead of sleep_for().After the philosopher’s thread thinking time ends, he “gets his first fork”. See line 24. We use a function lock() to perform the “gets fork” thing. Currently, the function lock() is very simple because we don’t know better. We just set the fork resource to the value 1. See line 10. After the philosopher thread obtained his first fork, he proudly announces the new state with a.”got ma” console output. Now the thread “gets his second fork”. See line 28. The corresponding console output is “got mb“. The next state is “he eats“. Again, we determine the duration, produce a console output, and occupy the thread with a sleep_for(). See line 31. After the state.”he eats” the philosopher puts down his forks. See lines 35 and 14. The unlock() function is again really simple and sets the resource back to 0.
Please compile the program without compiler optimization. We will see the reason later. The console output of our program looks promising:
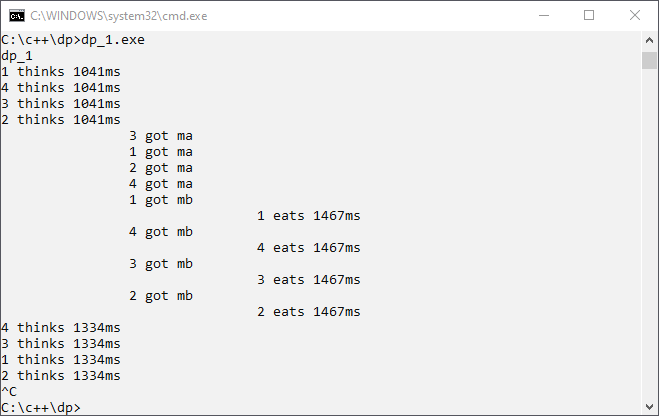
Have we already solved the dining philosophers’ problem? Well, the program output is not detailed enough to answer this question.
Multiple Resource Use with Logging
We should add some more logging. Currently, the function lock() does not check if the fork is available before the resource is used. The improved version of lock() in program dp_2.cpp is:
void lock(int& m) { if (m) { std::cout<<"\t\t\t\t\t\tERROR lock\n"; } m=1; }
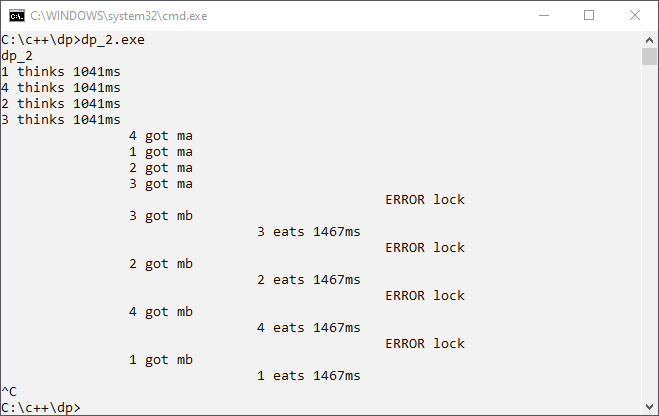
We see “ERROR lock” console output. This output tells us that two philosophers use the same resource simultaneously. What can we do?
Erroneous Busy Waiting without Resource Hierarchy
We can change the if statement in lock() into a while statement. This while statement produces a spinlock. A spinlock is a fancy word for busy waiting. While the fork resource is in use, the thread is busy waiting for a change from the state in use to the state available. At this very moment, we set the fork resource again to state in use. In the program, dp_3.cpp we have:
void lock(int& m) { while (m) ; // busy waiting m=1; }
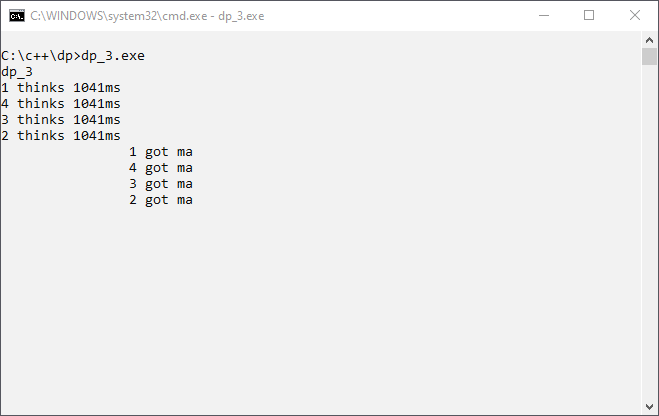
Every philosopher thread takes his first fork resource and then can not take the second fork. What can we do? Andrew S. Tanenbaum wrote, “Another way to avoid the circular wait is to provide a global numbering of all the resources. The rule is this: processes can request resources whenever they want to, but all requests must be made in numerical order.” [ref 2006; Tanenbaum; Operating Systems. Design and Implementation, 3rd edition; chapter 3.3.5]
Erroneous Busy Waiting with Resource Hierarchy
This solution is known as resource hierarchy or partial ordering. For the dining philosopher’s problem, partial ordering is easy. The first fork taken has to be the fork with the lower number. For philosophers 1 to 3, the resources are taken in the correct order. Only philosopher thread 4 needs a change for correct partial ordering. First, get fork resource 1, then get fork resource 4. See the main program in the file dp_4.cpp:
int main() { std::cout<<"dp_4\n"; srand(time(nullptr)); int m1{0}, m2{0}, m3{0}, m4{0}; std::thread t1([&] {phil(1, m1, m2);}); std::thread t2([&] {phil(2, m2, m3);}); std::thread t3([&] {phil(3, m3, m4);}); std::thread t4([&] {phil(4, m1, m4);}); t1.join(); t2.join(); t3.join(); t4.join(); }
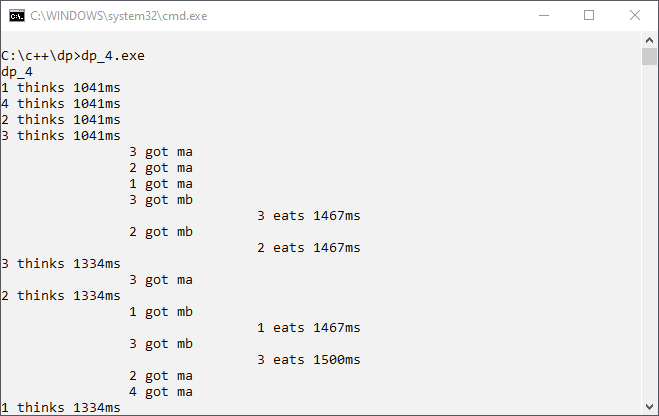
Now there is no longer wrong resource usage nor do we have a deadlock. We get brave and use compiler optimization. We want to have a good program that executes fast! This is program version 4 output with compiler optimization:
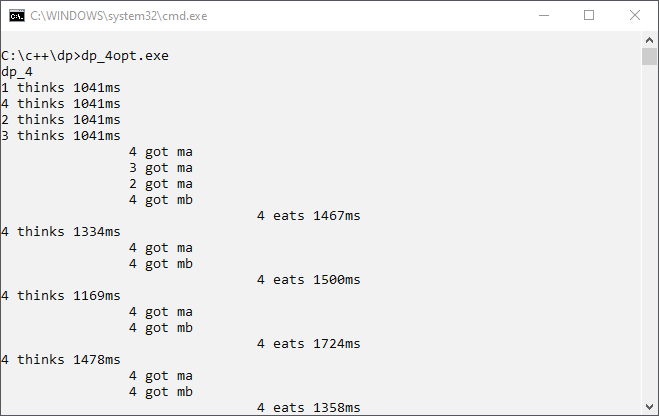
It is always the same philosopher thread that eats. Is it possible that the setting of compiler optimization can change the behavior of a program? Yes, it is possible. The philosopher threads read from memory the value of fork resource. The compiler optimization optimizes some of these memory reads away. Everything has a price!
Still Erroneous Busy Waiting with Resource Hierarchy
The programming language C++ has the atomic template to define an atomic type. The behavior is well-defined if one thread writes to an atomic object while another reads from it. In the file dp_5.cpp we use atomic<int> for the fork resources. See lines 11, 17, 21, and 47. We include <atomic> in line 5:
// dp_5.cpp #include <iostream> #include <thread> #include <chrono> #include <atomic> int myrand(int min, int max) { return rand()%(max-min)+min; } void lock(std::atomic<int>& m) { while (m) ; // busy waiting m=1; } void unlock(std::atomic<int>& m) { m=0; } void phil(int ph, std::atomic<int>& ma, std::atomic<int>& mb) { while(true) { int duration=myrand(1000, 2000); std::cout<<ph<<" thinks "<<duration<<"ms\n"; std::this_thread::sleep_for(std::chrono::milliseconds(duration)); lock(ma); std::cout<<"\t\t"<<ph<<" got ma\n"; std::this_thread::sleep_for(std::chrono::milliseconds(1000)); lock(mb); std::cout<<"\t\t"<<ph<<" got mb\n"; duration=myrand(1000, 2000); std::cout<<"\t\t\t\t"<<ph<<" eats "<<duration<<"ms\n"; std::this_thread::sleep_for(std::chrono::milliseconds(duration)); unlock(mb); unlock(ma); } } int main() { std::cout<<"dp_5\n"; srand(time(nullptr)); std::atomic<int> m1{0}, m2{0}, m3{0}, m4{0}; std::thread t1([&] {phil(1, m1, m2);}); std::thread t2([&] {phil(2, m2, m3);}); std::thread t3([&] {phil(3, m3, m4);}); std::thread t4([&] {phil(4, m1, m4);}); t1.join(); t2.join(); t3.join(); t4.join(); }
The program version 5 output is:

What’s next?
The next installment of this dining philosopher problem solves the tiny chance of misbehavior. So far, none of the programs have been correct.
Thanks a lot to my Patreon Supporters: Matt Braun, Roman Postanciuc, Tobias Zindl, G Prvulovic, Reinhold Dröge, Abernitzke, Frank Grimm, Sakib, Broeserl, António Pina, Sergey Agafyin, Андрей Бурмистров, Jake, GS, Lawton Shoemake, Jozo Leko, John Breland, Venkat Nandam, Jose Francisco, Douglas Tinkham, Kuchlong Kuchlong, Robert Blanch, Truels Wissneth, Mario Luoni, Friedrich Huber, lennonli, Pramod Tikare Muralidhara, Peter Ware, Daniel Hufschläger, Alessandro Pezzato, Bob Perry, Satish Vangipuram, Andi Ireland, Richard Ohnemus, Michael Dunsky, Leo Goodstadt, John Wiederhirn, Yacob Cohen-Arazi, Florian Tischler, Robin Furness, Michael Young, Holger Detering, Bernd Mühlhaus, Stephen Kelley, Kyle Dean, Tusar Palauri, Juan Dent, George Liao, Daniel Ceperley, Jon T Hess, Stephen Totten, Wolfgang Fütterer, Matthias Grün, Ben Atakora, Ann Shatoff, Rob North, Bhavith C Achar, Marco Parri Empoli, Philipp Lenk, Charles-Jianye Chen, Keith Jeffery, Matt Godbolt, Honey Sukesan, bruce_lee_wayne, Silviu Ardelean, schnapper79, Seeker, and Sundareswaran Senthilvel.
Thanks, in particular, to Jon Hess, Lakshman, Christian Wittenhorst, Sherhy Pyton, Dendi Suhubdy, Sudhakar Belagurusamy, Richard Sargeant, Rusty Fleming, John Nebel, Mipko, Alicja Kaminska, Slavko Radman, and David Poole.
| My special thanks to Embarcadero |  |
| My special thanks to PVS-Studio |  |
| My special thanks to Tipi.build |  |
| My special thanks to Take Up Code |  |
| My special thanks to SHAVEDYAKS |
Modernes C++ GmbH
Modernes C++ Mentoring (English)
Rainer Grimm
Yalovastraße 20
72108 Rottenburg
Mail: schulung@ModernesCpp.de
Mentoring: www.ModernesCpp.org



Leave a Reply
Want to join the discussion?Feel free to contribute!